Os riscos de latência no Kafka Share Groups ao utilizar record_limit
Aprofundamento CEVIU
Aprofundamento
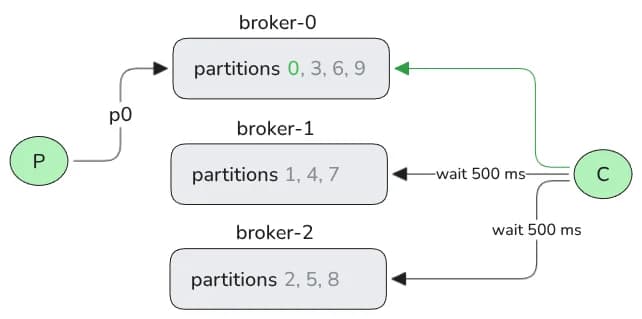
A modalidade `record_limit` nos Kafka Share Groups, quando combinada com um número de consumidores inferior ao de partições e submetida a cenários de distribuição desigual de dados (partition skew), pode levar a latências significativas. Isso ocorre porque o `record_limit` força um comportamento de busca de dados round-robin entre brokers. Nessas condições, se algumas partições estão vazias enquanto outras acumulam dados, o consumidor pode gastar o tempo de espera configurado em `fetch.max.wait.ms` (padrão de 500ms) em buscas infrutíferas em brokers sem dados. Essas esperas ocorrem repetidamente, prejudicando a taxa de consumo, especialmente durante a drenagem de backlogs ou em cargas de trabalho com alta temporalidade ou desbalanceamento.
O artigo original detalha como a combinação de `record_limit`, menos consumidores que partições e partition skew resulta em esperas patológicas. Ao buscar registros em modo round-robin para partições distribuídas em diferentes brokers, um consumidor pode enfrentar atrasos de 500ms em buscas vazias, enquanto dados continuam a chegar em partições mais carregadas. Cenários como drenagem de backlogs massivos (400 milhões de registros) ou cargas de trabalho com distribuição Zipfiana extrema demonstraram que o consumo pode cair drasticamente, de milhões para poucos milhares de registros por segundo, necessitando de horas para limpar um volume de dados que, em condições ideais, seria resolvido rapidamente.
O que mudou
A cobertura anterior se concentra na identificação e nos sintomas do problema de latência com `record_limit` em Kafka Share Groups. O artigo original, de Jack Vanlightly, detalha as causas técnicas e apresenta evidências de benchmark. Não há informação sobre uma correção específica ou uma nova versão que resolva este problema no momento, mas o Jira [KAFKA-20460](https://issues.apache.org/jira/browse/KAFKA-20460) indica que 'potential delivery slow-down for record-limit share consumers when draining record backlog' está em andamento ('In Progress') e ainda sem versão de correção definida. Um Pull Request para o Kafka (KAFKA-19929) com o título 'Fix polling delay for share consumer in record-limit mode' foi merged em novembro de 2025, sugerindo que melhorias no comportamento de polling round-robin podem ter sido implementadas ou estão em desenvolvimento, mas a aplicação exata dessas correções ao problema específico de 'pathological fetch waits' ainda depende de futuras avaliações.
Por que isso importa
Entender essas latências é crucial para engenheiros de dados e de sistemas distribuídos que utilizam Kafka para processamento de eventos em tempo real. A configuração inadequada pode levar a falhas em SLAs de latência, gargalos inesperados e dificuldades na recuperação de sistemas após picos de carga ou falhas. Ao identificar o `record_limit` como um gatilho potencial para essas esperas patológicas sob desbalanceamento, as equipes podem tomar decisões mais informadas sobre a configuração de seus Share Groups, evitando problemas de desempenho com o número de consumidores e partições.
A principal recomendação para mitigar esse problema, conforme apontado pelo autor e confirmado pelo Jira, é garantir que o número de consumidores seja igual ou superior ao número de partições quando `record_limit` é utilizado. Alternativamente, outras mitigações secundárias envolvem ajustes em `fetch.max.wait.ms` ou `max.poll.records`, com a ressalva de que estas podem introduzir outros trade-offs, como aumento do tráfego de requisições para os brokers ou incapacidade de gerenciar grandes volumes de dados em partições específicas.
Linha do tempo
Pull request KAFKA-19929 para corrigir delay de polling em record-limit merged.
Publicado artigo 'Kafka Share Groups, Pathological fetch waits with record_limit' por Jack Vanlightly.
Notícia: Os riscos de latência no Kafka Share Groups ao utilizar record_limit.
Perguntas frequentes
O que são Kafka Share Groups e qual a diferença entre `batch_optimized` e `record_limit`?
Share Groups permitem que múltiplos consumidores processem a mesma partição de um tópico Kafka. O modo `batch_optimized` permite que consumidores adquiram registros em lotes inteiros, com `max.poll.records` como um limite flexível, e realizam buscas em paralelo para partições em diferentes brokers. Já o `record_limit` adquire registros em fatias menores, com `max.poll.records` como um limite estrito, e as buscas são feitas em modo round-robin, uma de cada vez, para partições em diferentes brokers.
Qual a causa principal da latência elevada nos Kafka Share Groups com `record_limit`?
O problema surge com `record_limit` quando há menos consumidores que partições e ocorre desbalanceamento na distribuição de dados (partition skew). O modo de busca round-robin faz com que os consumidores esperem o `fetch.max.wait.ms` completo em brokers que podem não ter dados para suas partições atribuídas, enquanto outras partições acumulam registros, levando a 'esperas patológicas' e lentidão.
Qual a mitigação mais recomendada para evitar essas latências?
A mitigação primária e mais eficaz é garantir que o número de consumidores seja igual ou superior ao número de partições ao utilizar `record_limit`. Isso evita o cenário de round-robin infrutífero em partições vazias, resolvendo diretamente a causa das esperas patológicas.
Existem outras formas de mitigar o problema além de igualar consumidores e partições?
Sim, como mitigação secundária, pode-se considerar reduzir `fetch.max.wait.ms` (com risco de sobrecarregar brokers) ou aumentar `max.poll.records` (ajuda em casos de alta carga em partições específicas). Ajustar a distribuição de dados para reduzir o skew também é uma abordagem, embora nem sempre viável.
Fontes
- jack-vanlightly.comfonte original
- Categoria
- CEVIU Dados
- Publicado
- 29 de junho de 2026
- Editoria
- CEVIU Dados