Como o Manticore reconstruiu sua integração com ONNX para gerar embeddings até 14 vezes mais rápido
Aprofundamento CEVIU
Aprofundamento
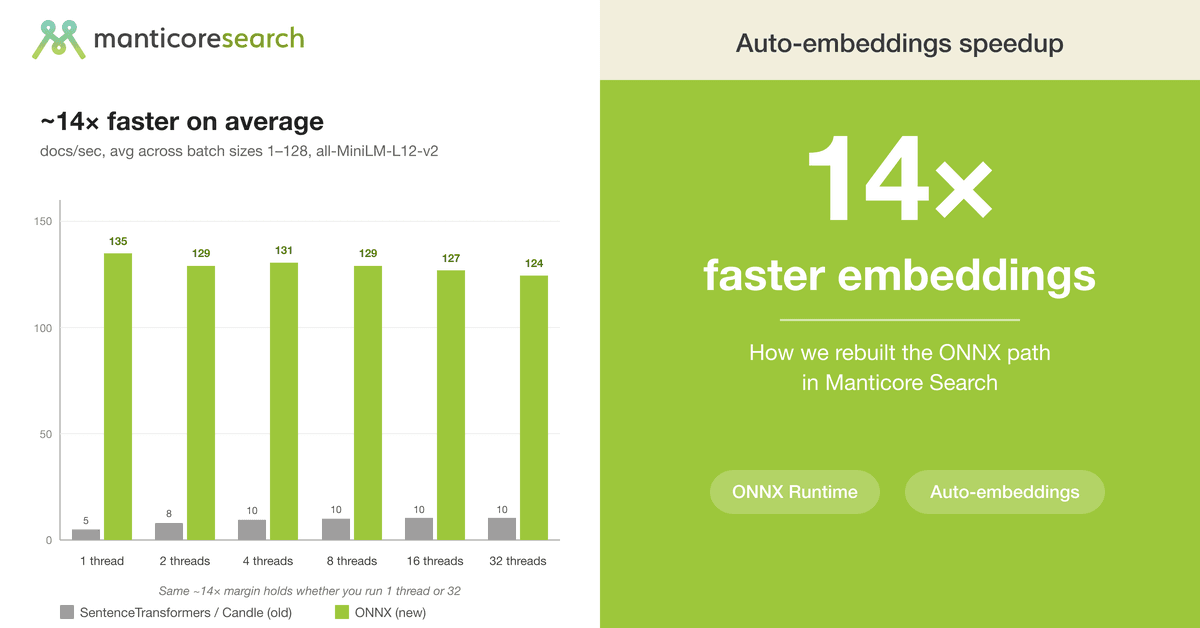
O Manticore Search implementou uma otimização significativa em seu pipeline de embeddings com a introdução de um novo backend baseado em ONNX Runtime (ORT). Anteriormente, recursos como o Auto Embeddings utilizavam a biblioteca Candle da Hugging Face, o que resultava em gargalos de performance e subutilização de CPU. A transição para ONNX Runtime, aproveitando modelos como all-MiniLM-L12-v2, promete um salto de desempenho, com a equipe relatando até 14 vezes mais velocidade em testes comparativos. O foco técnico está na reconfiguração da execução de modelos, otimizando o uso de threads e a gestão de sessões para processamento de vetores de texto.
A arquitetura anterior sofria com contenção de locks em sessões compartilhadas e overhead de padding em lotes de documentos com tamanhos variáveis. A Manticore abordou isso compartilhando uma única instância thread-safe do ONNX Runtime em sistemas Linux e macOS, habilitando o uso simultâneo por múltiplos clientes sem locks. A configuração de `intra_op_spinning(false)` foi crucial para evitar que threads ficassem ociosas consumindo CPU desnecessariamente. Ao invés de lotes internos (batching), a abordagem agora processa documentos individualmente, minimizando o impacto da variabilidade no comprimento dos textos e o gargalo de paralelismo.
O que mudou
A principal mudança é a substituição do pipeline de embeddings baseado em Candle pelo ONNX Runtime (ORT) na versão 27.1.5 do Manticore Search. Essa atualização abandonou a estratégia de processamento em lote de documentos e a modelo de sessão serializada ou em pool em favor de uma única sessão ORT thread-safe (em sistemas não-Windows) e processamento individual por documento. A otimização `intra_op_spinning(false)` foi desativada, permitindo que threads liberem a CPU quando ociosas, em vez de manterem loops de espera. Em sistemas Windows, onde o modelo thread-safe não é totalmente estável, o Manticore implementou um travamento (locking) em nível de closure, não apenas na chamada de execução, para evitar condições de corrida.
Para o usuário final, a interatividade sobre o desempenho do Auto Embeddings muda drasticamente. Se antes o limite era de 5 a 11 documentos por segundo, com a nova implementação a faixa de performance sobe para 70 a 230 documentos por segundo. A estratégia de ingestão de dados também foi refinada: para obter o máximo throughput em cargas pesadas, recomenda-se o uso de grandes lotes (32-128) em uma única thread cliente, aproveitando o paralelismo interno do ORT. Para cargas de trabalho pontuais, a performance continua robusta, com latências significativamente menores.
Por que isso importa
Esta otimização no processamento de embeddings pela Manticore impacta diretamente a velocidade de ingestão e busca de dados vetoriais. Com o aumento de até 14x na performance, aplicações que dependem de buscas semânticas de baixa latência, como sistemas de recomendação, análise de sentimento e detecção de anomalias, se beneficiarão imensamente. A arquitetura aprimorada também melhora a eficiência no uso de recursos de hardware, entregando mais volume de processamento por unidade de CPU, o que pode se traduzir em redução de custos operacionais.
O foco em um pipeline de embeddings mais rápido e eficiente é uma tendência clara no ecossistema de bancos de dados vetoriais e de busca. Ao integrar ONNX Runtime de forma otimizada, o Manticore Search demonstra um compromisso com a vanguarda tecnológica, permitindo que desenvolvedores utilizem modelos de embedding populares de forma mais performática diretamente em suas bases de dados, sem a necessidade de serviços externos complexos para a inferência do modelo.
Linha do tempo
Publicação do artigo '14× faster embeddings: how we rebuilt the ONNX path in Manticore'.
Lançamento do Manticore Search 27.1.5 com o novo backend ONNX otimizado.
Perguntas frequentes
Qual a principal vantagem da nova integração ONNX no Manticore Search?
A principal vantagem é um aumento drástico na velocidade de processamento de embeddings, podendo ser até 14 vezes mais rápido que o método anterior. Isso resulta em melhor performance para ingestão e busca de dados vetoriais.
Como o Manticore atingiu essa melhoria de performance?
Através da otimização do uso do ONNX Runtime, que inclui o compartilhamento de uma única sessão thread-safe, a desativação do spinning intra-op e o processamento individual de documentos para evitar gargalos de concorrência e overhead de padding.
Em que versões do Manticore Search essa otimização está disponível?
A nova arquitetura com ONNX Runtime foi introduzida no Manticore Search 27.1.5 e se tornou o caminho padrão para modelos HuggingFace que já possuem um arquivo .onnx.
Quais os impactos práticos para quem usa Manticore Search?
A ingestão e busca de dados vetoriais se tornam significativamente mais rápidas. Users podem esperar uma throughput muito maior e latências menores, especialmente ao otimizar a estratégia de ingestão com grandes lotes (batches) em uma única thread para cargas pesadas.
Fontes
- manticoresearch.comfonte original
- Categoria
- CEVIU Dados
- Publicado
- 29 de junho de 2026
- Editoria
- CEVIU Dados