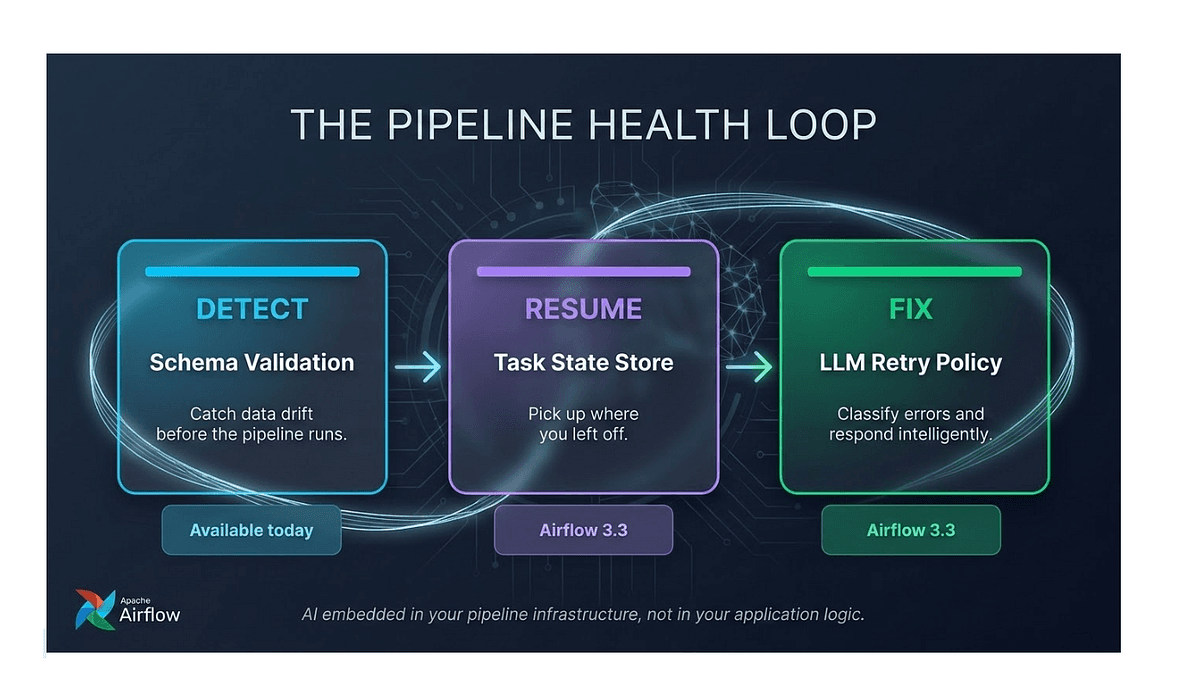
O Apache Airflow está introduzindo um conjunto de três novos controles baseados em IA que visam otimizar a resiliência dos pipelines de dados, reduzindo significativamente as interrupções. As inovações incluem validação semântica de schema, que detecta desvios, e um sistema de gerenciamento de estado persistente para facilitar a reconexão e recuperação de jobs falhos, preservando identificadores externos. Além disso, o Airflow integrará um mecanismo de decisão de retry baseado em LLM para classificar falhas e determinar se um job deve ser retentado, atrasado ou escalado, prometendo uma engenharia de dados mais robusta e menos complexa.
O GitHub revelou que a introdução de ferramentas de code review mais eficientes para o Copilot inicialmente resultou em uma piora nos benchmarks, com aumento dos custos de token e menor identificação de problemas. O gargalo se deu porque as instruções genéricas direcionavam o agente a navegar por todo o repositório, em vez de focar no *diff* inicial. A solução veio com a reescrita das instruções para priorizar o *diff*, refinando a busca com comandos como *grep* e *glob*, e validando evidências com *view*. Essa otimização reduziu o custo médio de revisão em 20%, mantendo a qualidade.
O Lakekeeper apresenta uma API de Tabela Genérica que permite que ativos de dados fora do padrão Iceberg, como datasets Lance, sejam gerenciados como objetos catalogados e governáveis, eliminando a necessidade de conversão direta para o formato Iceberg. A solução centraliza o armazenamento de metadados cruciais e aproveita os mecanismos de catálogo do Iceberg, provendo gestão unificada para controle de acesso, ciclo de vida dos dados e credenciais com escopo definido. Essa abordagem simplifica a governança de dados em ecossistemas heterogêneos, ampliando a capacidade de integração de diferentes formatos de dados.
Uma análise recente da SQLSure revelou que benchmarks amplamente utilizados para modelos de text-to-SQL, como BIRD e Spider, contêm chaves de resposta ('gold queries') incorretas. Esse problema impacta diretamente a avaliação da acurácia dos modelos, podendo levar a uma situação onde sistemas são recompensados por replicar erros inerentes aos benchmarks, enquanto respostas corretas são indevidamente penalizadas. A empresa argumenta que a validação desses modelos deve ir além da simples execução, incorporando uma verificação rigorosa da semântica dos dados, incluindo cardinalidade de junções, granularidade e aditividade, para garantir avaliações mais precisas e justas.
A Affirm realizou uma reengenharia significativa em sua plataforma de mensagens de pré-checkout, substituindo uma arquitetura monolítica em Python por um microsserviço em Kotlin, integrado a um motor de regras avançado. A transformação resultou em uma impressionante redução de 50% na latência P99 e, crucialmente, diminuiu o tempo de configuração de novos experimentos de longos dois meses para apenas quatro dias. Essa otimização é um marco, pois a criação de experimentos agora se resume à configuração de regras com base em atributos pré-existentes, eliminando a complexidade de desenvolvimento de código e ciclos de deployment prolongados.
O ClickHouse anuncia a disponibilização de imagens Docker fortificadas, fundamentadas em uma arquitetura mínima que elimina shell, gerenciador de pacotes e ferramentas de rede. Esta medida resultou na erradicação de vulnerabilidades de segurança de média gravidade (CVEs), reduzindo de oito na imagem padrão do Ubuntu para zero, sem comprometer a funcionalidade do banco de dados. A adoção dessas imagens otimizadas requer apenas uma pequena alteração no comando `docker run`, e uma versão de depuração está disponível para anexar ferramentas temporariamente, mantendo a integridade da imagem de produção.
A nova versão do Manifesto Shift Left reforça a tese de que a engenharia de software deve priorizar a proveniência de dados desde sua origem, no código do produtor, e não apenas nos *data warehouses*. Essa abordagem permite rastrear a linhagem de dados em nível de código, atrelada aos *releases*, revelando a propriedade, fluxos de dados sensíveis, dependências semânticas e o impacto de mudanças diretamente nos *pull requests*. Isso transforma a governança, a rastreabilidade para modelos de IA, a análise de impacto e as auditorias em processos contínuos, algo crucial frente à aceleração de mudanças por agentes de codificação.
Empresas sem profissionais dedicados à propriedade de produtos de dados desperdiçam 45% do tempo da equipe em tarefas reativas, contrastando com os 27% observados em equipes com responsabilidades bem definidas. Essa disparidade surge quando organizações falham em designar donos claros para dashboards, conjuntos de dados ou modelos. A adoção de ferramentas de IA intensifica essa diferença: equipes com propriedade estabelecida registram um aumento de 18 pontos percentuais no sentimento positivo, enquanto aquelas sem essa clareza experimentam uma queda de 26 pontos, evidenciando o impacto crítico da governança de dados na eficácia e percepção do trabalho.
O PostgreSQL demonstra capacidade de realizar o pruning de partições de forma eficiente, mesmo quando as consultas envolvem filtros em colunas que não são chaves de partição. Essa otimização é viável ao correlacionar colunas com intervalos previsíveis e a chave de partição. A implementação de constraints do tipo CHECK, especificando esses intervalos e tratando valores atípicos em faixas separadas, permite que o otimizador ignore partições irrelevantes. Tal abordagem evita a varredura desnecessária de todos os índices locais, resultando em uma melhoria significativa no desempenho das consultas.
A Arcesium, gigante em serviços financeiros e de tecnologia, transformou seu data warehousing ao migrar um repositório de P&L de 170TB e 15 trilhões de registros de um RDBMS tradicional para uma arquitetura baseada em Apache Iceberg no S3, orquestrada por DuckDB. Essa transição estratégica, que incluiu o desenvolvimento da camada Swiftlake e a adoção de KEDA para autoescalonamento no Kubernetes, resultou em uma impressionante redução de 80% no tempo de ingestão para grandes carteiras. Além disso, a empresa conseguiu minimizar timeouts de egress e otimizar custos de infraestrutura em aproximadamente 40%, aproveitando ainda os recursos de time-travel do Iceberg para recuperação de dados.
A Databricks conduziu uma avaliação interna detalhada de agentes de codificação, utilizando suas próprias tarefas operacionais como benchmark. Os resultados indicaram que diversos modelos de IA, inclusive soluções de código aberto como o GLM 5.2, demonstraram desempenho robusto. Este estudo é crucial para a otimização de pipelines de dados e processamento, além de influenciar futuras arquiteturas de modelagem e estratégias de governança de dados.
A Anthropic lançou o Claude Science AI Workbench, uma plataforma que visa transformar o papel da IA no ambiente científico. Projetada para atuar como uma parceira colaborativa, a ferramenta oferece suporte abrangente em diversas etapas da pesquisa, desde a revisão bibliográfica e a formulação de hipóteses até a análise de dados, o design experimental e a escrita de código. A iniciativa busca posicionar a IA como um catalisador para descobertas, otimizando o fluxo de trabalho de cientistas e pesquisadores.
A Meta acaba de divulgar seu inovador Blueprint de Armazenamento de IA, revelando os segredos por trás de sua robusta infraestrutura de dados para IA. A empresa detalhou a complexa arquitetura interna e as valiosas lições aprendidas na gestão de um sistema de armazenamento massivo. Dentre os destaques, a Meta enfatiza uma hierarquia de armazenamento multinível, estratégias avançadas de posicionamento e replicação de dados, camadas de caching altamente sofisticadas, o uso inteligente de *erasure coding* para garantir eficiência e durabilidade, e otimizações de rede que garantem alta performance.
A Grab, gigante do sudeste asiático, migrou com sucesso seu Counter Service antifraude de um banco de dados de coluna larga para o Aerospike, um NoSQL de alta performance. A transição foi concluída sem interrupções, empregando estratégias como facades de armazenamento, leituras/escritas em sombra e divisão determinística de tráfego. A otimização incluiu a substituição do armazenamento por bucket para mapas ordenados por contador, o que minimizou a cardinalidade dos registros e o uso de disco. Essas mudanças resultaram em uma melhoria de aproximadamente 50% na latência de leitura p99 em produção e uma significativa redução nos custos por nó.
A Redis publicou uma análise detalhada dos principais bancos de dados vetoriais de código aberto, como Redis, Weaviate, Qdrant, Milvus, Chroma e LanceDB. A avaliação, fundamentada em benchmarks e cenários de produção, aponta o Redis como superior em baixa latência e alto QPS para buscas híbridas e filtragens. Qdrant e Weaviate se sobressaíram na filtragem de metadados complexos e na experiência de desenvolvimento, enquanto Milvus demonstrou liderança em escalabilidade para volumes massivos de dados.
A Vercel, renomada plataforma de desenvolvimento web, implementou uma estratégia inovadora para qualificação de leads, transformando uma equipe de 10 SDRs em um equivalente de 1,25 pessoas. Este feito, que gerou um ROI de 32x, foi alcançado através de um modelo de engenharia GTM que integra um engenheiro, um cientista de dados e um especialista de domínio. A abordagem foca na documentação de fluxos de trabalho de melhores práticas, QA em 'shadow mode' e a remoção gradual da intervenção humana em tarefas determinísticas. O sucesso dessa automação é suportado por APIs composable, MCP (Multi-Cloud Platform), webhooks, uma camada semântica robusta e infraestrutura escalável para lidar com cargas de trabalho massivas sem disparar custos, evidenciando o poder da IA na otimização de processos de vendas.
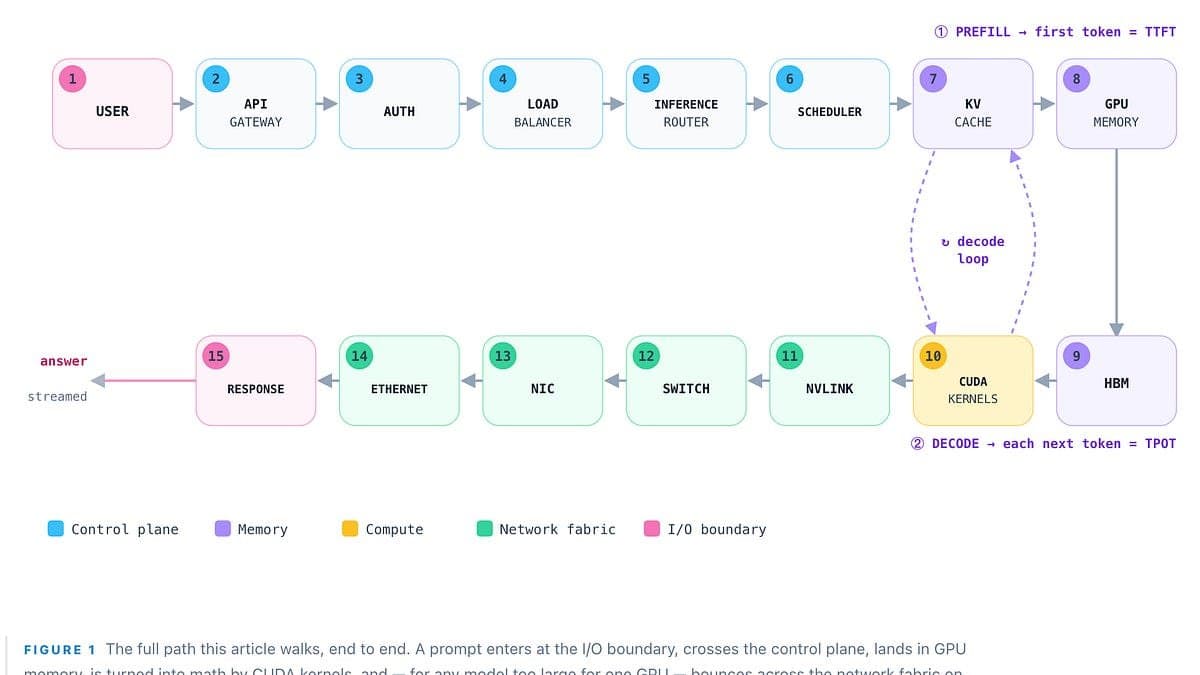
A inferência de IA se consolidou como o principal vetor de custos em operações de Inteligência Artificial, representando cerca de dois terços do consumo computacional e até 90% do custo total de vida útil de um modelo. A otimização econômica dessa etapa está diretamente ligada ao custo por token e à latência, com o pré-carregamento (prefill) limitado pela capacidade computacional e a decodificação restrita pela largura de banda da memória. Técnicas como gestão de KV cache, batching, quantização e decodificação especulativa emergem como alavancas cruciais para aprimorar essa equação, mas a vantagem competitiva a longo prazo reside na superação de gargalos físicos como largura de banda HBM, fabric NVLink/scale-up, sistemas ópticos e consumo energético.
A Anthropic tem avançado com modelos de IA mais sofisticados, capazes de resolver tarefas complexas. No entanto, esses modelos recentes demonstram uma 'regressão' na interação com ferramentas, introduzindo campos inválidos em esquemas mais rigorosos. A hipótese é que esses modelos estejam 'overfit' ao formato de ferramentas mais permissivo do Claude Code. Para mitigar essa questão, sugere-se que as plataformas de 'agent harnesses' implementem validações de esquema mais estritas ou adotem chamadas de ferramenta mais restritas, garantindo assim a integridade e confiabilidade das saídas geradas.
A engenharia de contexto desponta como um avanço fundamental na engenharia de analytics, concentrando-se na organização do conhecimento corporativo para que agentes de IA possam fornecer respostas confiáveis em linguagem natural. A chave para aprimorar a confiabilidade reside na estruturação de modelos de dados robustos e documentação clara, que podem elevar a precisão de um agente de 40% para 90%. Curiosamente, logs de query e profiling demonstram menor impacto nesse aumento de acurácia. A metodologia sugere iniciar com 10 a 20 tabelas de alto valor, integrar testes em CI/CD, gerenciar o contexto como um repositório Git baseado em Markdown, e estabelecer governança para permissões, avaliações e otimização de custos de token.
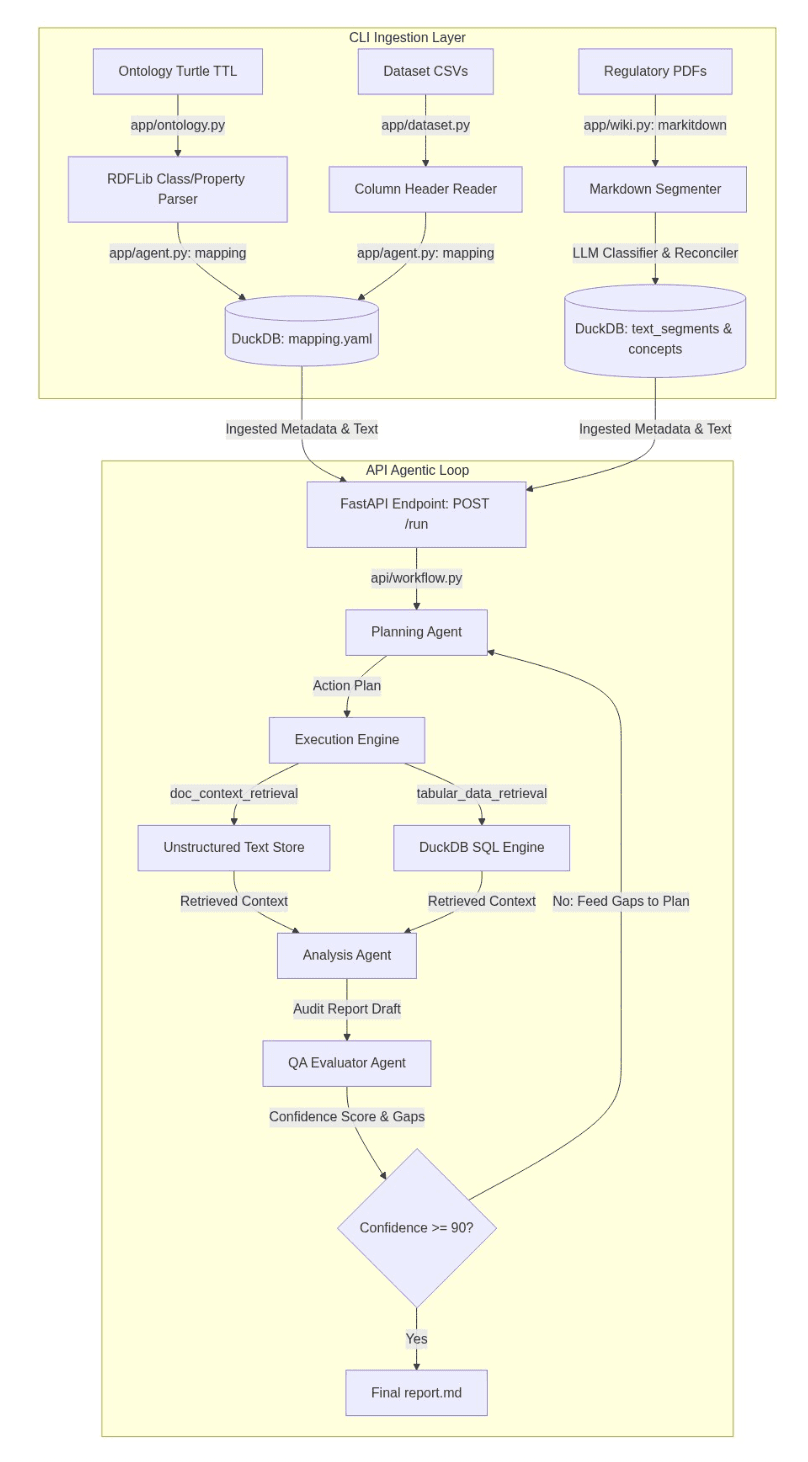
A auditoria de conformidade e risco ganha um novo patamar de automação ao integrar documentos de políticas não estruturados com dados estruturados de data warehouses e bancos de dados. Um workflow baseado em IA, utilizando mapeamentos de ontologias OWL/FIBO e análise de PDFs regulatórios convertidos para Markdown, emprega modelos LLM-Wiki e Text2SQL. Este sistema planeja, consulta, analisa e se auto-corrige até atingir um nível de confiança superior a 80%, prometendo agilizar processos críticos e otimizar a gestão de riscos.