A Vercel revelou um dado promissor para o ecossistema de Inteligência Artificial de código aberto: em junho, modelos open-weight responderam por 29% do volume total de tokens processados em seu AI Gateway. Mais notável ainda é o impacto financeiro: esses modelos representaram menos de 4% dos custos operacionais, sublinhando sua crescente eficiência e um ponto de inflexão na adoção de soluções de IA mais acessíveis e flexíveis.
A Sakana AI expande sua pesquisa em inteligência coletiva para o mundo físico com os inovadores "Smart Cellular Bricks". Esses blocos, capazes de se comunicar localmente e empregar redes neurais, classificam e reconstroem formas 3D de maneira autônoma, dispensando controle centralizado. Testes revelaram alta precisão na classificação de formas e notável resiliência a ruídos e falhas de módulos, marcando um avanço significativo na interação entre IA e hardware modular.
Pesquisadores da DeepMind revelaram o GenCeption, um sistema inovador que converte um modelo de geração de vídeo pré-treinado em um modelo de visão unificado. Controlado por instruções textuais, essa abordagem permite que uma única arquitetura execute diversas tarefas de visão computacional, capitalizando a rica compreensão visual já inerente aos modelos de geração de vídeo. O GenCeption promete simplificar o desenvolvimento e a aplicação de soluções de IA visual, ao consolidar múltiplas funcionalidades em um só modelo.
Zvi Mowshowitz aponta o GPT-5.6 Sol como o modelo de linguagem que melhor equilibra raciocínio de alta qualidade, velocidade de processamento e custo-benefício entre os "frontier models" atuais. Essa combinação o posiciona como a escolha ideal para tarefas que exigem conhecimento aprofundado, caracterizando-o como um verdadeiro "cavalo de batalha" da IA. Mowshowitz enfatiza sua capacidade de executar operações de longo prazo e otimizar o uso de recursos computacionais, inclusive em fluxos de trabalho "agentic". Contudo, ressalta a importância da seleção criteriosa de modelos para cada cenário, visando sempre a máxima performance.
Uma investigação detalhada sobre o Grok Build CLI oficial da xAI revelou uma prática preocupante: a ferramenta transmite e armazena os conteúdos dos arquivos lidos, enviando-os na íntegra e sem qualquer edição para os servidores da xAI. A CLI realiza o upload de repositórios completos, independentemente do que o agente de IA realmente processa. Os dados são depositados em um bucket do Google Cloud Storage, embora ainda não haja evidências de que a xAI utilize esses códigos para treinamento de seus modelos de IA.
A Prime Intellect anunciou o lançamento do verifiers v1, uma reformulação estratégica de sua arquitetura de ambiente, agora otimizada para a vanguarda do Aprendizado por Reforço (RL) e avaliações agentic. Esta atualização reorganiza os ambientes em coleções de tarefas, um *harness* e um *runtime*, capacitando a execução escalável de tarefas complexas para agentes autônomos. Dentre as capacidades aprimoradas estão atividades como codificação e interação com sistemas computacionais, abrindo novos horizontes para o desenvolvimento e testes de IA.
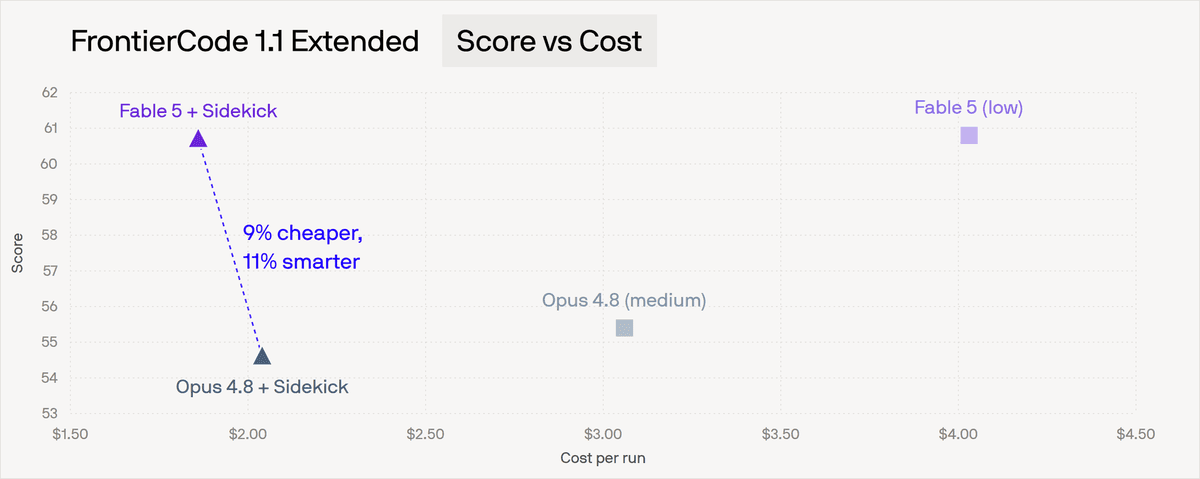
A Cognition inovou ao substituir o Opus 4.8 pelo Fable 5 na arquitetura do Devin, seu agente de IA, visando otimizar os custos operacionais. Apesar de o Fable 5 apresentar um custo por token mais elevado que o Opus 4.8, a empresa desenvolveu uma arquitetura engenhosa que não apenas tornou o Fable mais econômico na prática, mas também resultou em pontuações de desempenho superiores. Esta estratégia da Cognition destaca um avanço significativo na precificação e na viabilidade do trabalho de agentes de IA, prometendo impactar o mercado.
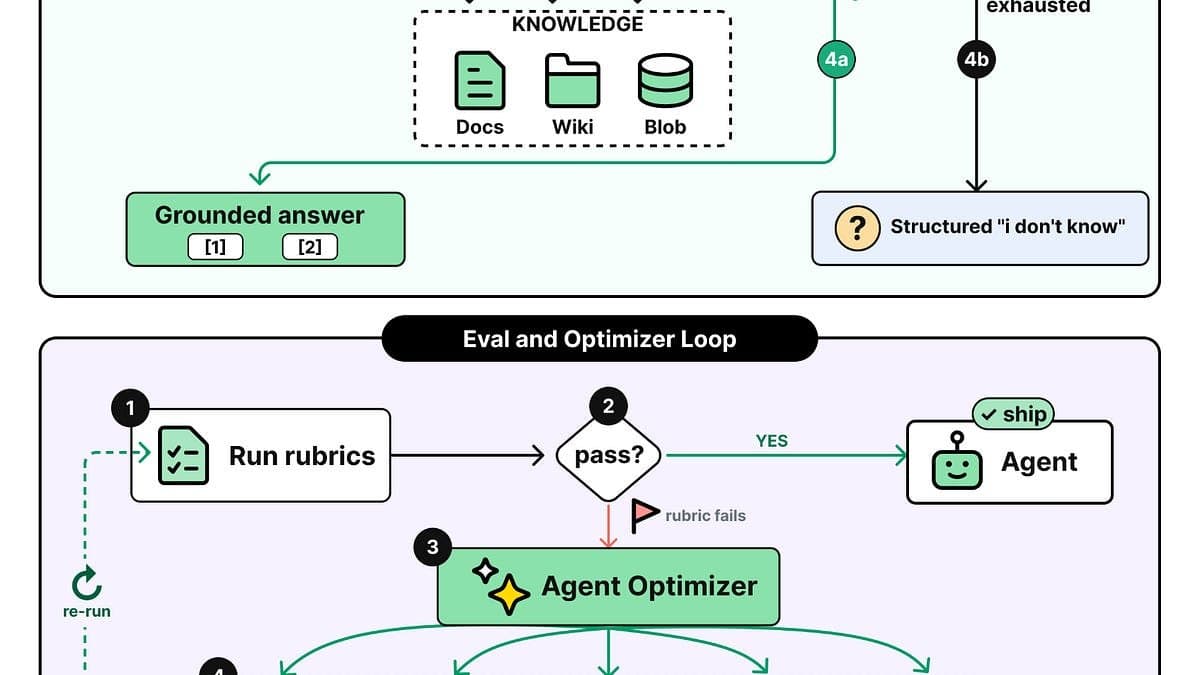
A Microsoft detalhou os pilares de sua infraestrutura e os mecanismos cruciais que permitem a operação de milhares de agentes de IA em larga escala nos produtos Foundry e Copilot. Entre as práticas essenciais, destacam-se o tratamento do processo de 'retrieval' como um sub-agente, a atribuição de identidades e 'workspaces' distintos para cada agente, e a implementação de avaliações baseadas em rubricas, com ciclos de melhoria automatizados, garantindo eficiência e escalabilidade na adoção da IA.
O Manus Auto-Publish surge como uma ferramenta essencial para desenvolvedores que buscam otimizar o ciclo de vida do software. A plataforma automatiza a implantação de builds bem-sucedidas em URLs ativas, eliminando a intervenção manual no processo de publicação. Essa funcionalidade promete maior agilidade e eficiência, reduzindo erros e liberando equipes para focar em inovação, um avanço significativo na gestão de projetos de IA e desenvolvimento contínuo.
Tom Blomfield, figura proeminente no cenário de startups e ex-sócio da Y Combinator (YC), solicitou licença de suas atividades na aceleradora para integrar a equipe da Anthropic. Ele se junta a Tom Brown no setor focado em otimização e desenvolvimento da infraestrutura de *compute* essencial para os modelos de IA da empresa. Essa movimentação sinaliza um fortalecimento da Anthropic em sua capacidade computacional e em sua corrida para aprimorar o desempenho de suas IAs.
A Inteligência Artificial desponta como uma ferramenta revolucionária, transpondo barreiras e capacitando indivíduos a inovar e criar, em vez de apenas consumir. Ela democratiza a produção, permitindo que pessoas sem conhecimento técnico aprofundado desenvolvam soluções práticas e criativas. Diferente de tecnologias voltadas para o consumo passivo, a IA estimula a individualidade e a criatividade, cultivando um ecossistema onde projetos e ideias pessoais podem florescer e se converter em contribuições significativas para a sociedade. Seu potencial reside em empoderar o criador que existe em cada um, redefinindo nossa interação com a tecnologia.
O Claude Code, ferramenta baseada em IA, foi atualizado com um navegador in-app inovador. Essa funcionalidade permite que a IA acesse e interaja diretamente com documentações, designs e websites, simulando a navegação humana e operando de forma similar ao acesso a servidores de desenvolvimento locais. O recurso é isolado em um ambiente sandbox e oferece configuração para persistência de sessões, garantindo maior segurança e personalização na interação com conteúdos online.
A equipe Frontier AI do Google Data Cloud está na vanguarda do desenvolvimento de uma nova metodologia robusta para avaliar agentes de IA. A abordagem, que integra a teoria da informação para modular a dificuldade dos cenários de teste, promete elevar significativamente a precisão na mensuração do desempenho desses sistemas autônomos, um passo crucial para o avanço e a confiabilidade da Inteligência Artificial.
A Apple iniciou um processo judicial contra a OpenAI e ex-executivos de sua própria equipe, alegando apropriação indevida de informações confidenciais sobre hardware. A denúncia aponta que a OpenAI teria se beneficiado desses dados para acelerar o desenvolvimento de seus próprios dispositivos. O processo detalha acusações de que líderes seniores da empresa instruíram funcionários a desrespeitar protocolos de segurança e a transferir informações sensíveis de produtos.
A empresa Cursor estaria desenvolvendo um agente de IA de uso geral com a capacidade de executar diversas tarefas, como responder e-mails, gerenciar mensagens de texto, organizar planilhas e auxiliar em funções de engenharia. A iniciativa aponta para um salto significativo na criação de sistemas mais autônomos e versáteis, prometendo otimizar operações cotidianas e profissionais por meio de uma IA integrada e adaptável a múltiplas demandas.
A OpenAI, gigante da Inteligência Artificial, passa por uma reestruturação em sua área de segurança. Johannes Heidecke, líder da equipe de sistemas de segurança, está de saída da empresa. Para assumir interinamente a importante função, Saachi Jain, que já possui experiência na gestão de equipes de segurança na própria OpenAI, foi designada. A movimentação indica uma reavaliação estratégica na abordagem da companhia em relação à segurança de suas IAs, um tema cada vez mais crítico para o setor.
Greg Brockman, cofundador da OpenAI, assume uma posição de liderança ainda mais central na empresa, passando a supervisionar projetos cruciais. Essa movimentação ocorre após a saída de Fidji Simo e em um momento estratégico para a gigante da IA, que busca otimizar a receita em meio à acirrada concorrência de players como Anthropic e Google. Com a possibilidade de um IPO no horizonte, a OpenAI se movimenta para fortalecer sua liderança e preparar a documentação regulatória, enquanto enfrenta o desafio da recente queda na participação de mercado do ChatGPT.
A gigante chinesa Tencent está novamente em negociações para adquirir a Manus, com o objetivo de reverter uma transação anterior envolvendo a Meta, que foi barrada por reguladores chineses. A meta é fechar o acordo pela mesma avaliação de US$ 2 bilhões. Esta aquisição representa uma oportunidade estratégica para a Tencent acessar tecnologia de ponta em agentes de IA, essencial para seus planos de expansão no setor. Recentemente, a empresa lançou um protótipo de agente que poderá atender a mais de um bilhão de usuários em seu vasto ecossistema, destacando a importância da Manus para fortalecer sua atuação em IA.
A OpenAI anunciou uma medida que certamente agradará seus usuários: a remoção temporária da limitação de uso de cinco horas para os planos Plus, Pro e Business do GPT-5.6 Sol. Adicionalmente, a empresa informou que o uso atual de todos os assinantes será redefinido, proporcionando maior liberdade e acesso irrestrito à potente IA. Essa iniciativa visa otimizar a experiência dos usuários que dependem da ferramenta para suas atividades profissionais e criativas.
A Meta descontinuou rapidamente seu novo recurso de imagem baseado em IA, o Muse Image, poucos dias após seu lançamento. A ferramenta, que permitia aos usuários gerar e modificar imagens utilizando conteúdo de contas públicas, enfrentou forte oposição e levantou preocupações significativas sobre privacidade e uso de dados. A decisão da empresa reflete a sensibilidade crescente em torno das aplicações de IA e a necessidade de abordar as expectativas dos usuários em relação à proteção de suas informações.