parquet-java: lançamento do Hardwood 1.0 traz leitor Apache Parquet rápido e leve para a JVM
Aprofundamento CEVIU
Aprofundamento
O Hardwood 1.0 chega como uma alternativa moderna e focada em performance ao tradicional leitor Apache Parquet para a JVM, o parquet-java. Desenvolvido do zero, o Hardwood se destaca por sua arquitetura leve, com zero dependências obrigatórias, exigindo apenas codecs específicos para compressões como Snappy ou Zstd. Isso contrasta com a stack mais robusta do parquet-java, que tradicionalmente carrega um número maior de dependências no classpath.
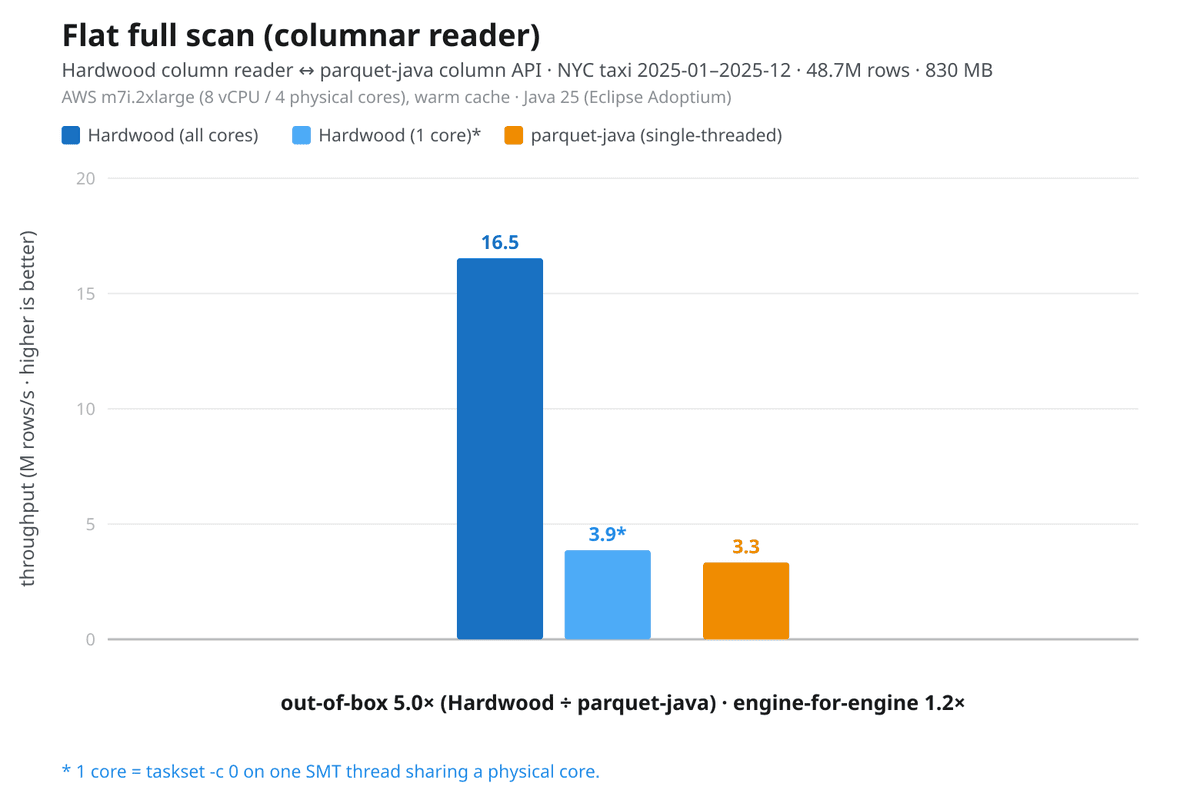
Uma das principais inovações do Hardwood é seu modelo de concorrência. Ao contrário do parquet-java, que é single-threaded em sua base, o Hardwood paraleliza a decodificação de páginas entre os núcleos da CPU por padrão. Essa abordagem resulta em tempos de processamento significativamente menores, especialmente em workloads analíticos. O projeto oferece duas APIs distintas para atender diferentes necessidades: uma API de leitura de linhas para acesso mais geral e uma API de lote de colunas focada em alta vazão, inspirada no Apache Arrow, ideal para processamento em larga escala e integração com outras ferramentas de computação distribuída.
O que mudou
O lançamento do Hardwood 1.0 marca a transição de um projeto em desenvolvimento ativo para uma solução pronta para produção. Após cinco releases prévias (Alpha1, Beta1, Beta2, CR1 e CR2), a versão 1.0.0.Final garante estabilidade e um foco em retrocompatibilidade da API pública. As novidades incluem suporte aprimorado para tipos lógicos do Parquet, como um primeiro passo em tipos geoespaciais, e a introdução de APIs mais refinadas para leitura de colunas em lote. Embora o Artigo-Fonte original mencione a ausência de suporte a Bloom Filters, o roadmap para versões futuras já aponta para a inclusão dessa funcionalidade, buscando otimizar ainda mais o 'predicate push-down' em cenários de alta cardinalidade.
Por que isso importa
Para engenheiros de dados e desenvolvedores JVM que lidam com grandes volumes de dados no formato Parquet, o Hardwood 1.0 representa uma evolução significativa. Sua leveza e performance multithreaded podem reduzir drasticamente os tempos de processamento e a pegada de dependências em aplicações, especialmente em ambientes com recursos limitados ou onde a latência é crítica. A capacidade de paralelizar a decodificação de páginas e a eficiência no 'predicate push-down' o tornam uma ferramenta poderosa para otimizar pipelines analíticos.
Além disso, a introdução de uma API de lote de colunas abre portas para integrações mais eficientes com frameworks de processamento distribuído e para o uso de técnicas de vetorização em loops de processamento. O projeto demonstra o poder de abordagens mais modernas e focadas em performance para tarefas de I/O de dados na JVM, contrastando com soluções mais estabelecidas como o parquet-java.
Repositório oficial: apache/parquet-java
Linha do tempo
Lançamento do Hardwood 1.0, focado em performance e leveza para JVM.
Perguntas frequentes
Qual a principal diferença entre Hardwood e parquet-java?
O Hardwood se diferencia por ser uma biblioteca leve, sem dependências obrigatórias, e por paralelizar a decodificação de páginas Parquet entre os núcleos da CPU por padrão. O parquet-java tradicionalmente carrega mais dependências e opera em um modelo single-threaded na sua base.
Quando devo usar o Hardwood 1.0 ou o parquet-java?
O Hardwood 1.0 é ideal para quem busca performance máxima, redução de dependências e concorrência multi-core. O parquet-java pode ser mais adequado para cenários onde o ecossistema Apache existente é um fator chave ou para projetos que ainda não podem adotar JDKs mais recentes (como Java 21+).
O que o Hardwood 1.0 oferece além da leitura de Parquet?
O Hardwood 1.0 inclui APIs de linha e de lote de colunas para diferentes necessidades de processamento. O projeto também disponibiliza uma ferramenta de linha de comando (CLI) para inspecionar e interagir com arquivos Parquet, incluindo um modo interativo chamado 'hardwood dive'.
Quais são as próximas funcionalidades planejadas para o Hardwood?
O roadmap inclui suporte para escrita de arquivos Parquet, otimizações de performance como Bloom Filters e String reuse, suporte a criptografia, melhorias na CLI e integrações com o ecossistema Java, como com o Apache Flink.
Fontes
- morling.devfonte original
- Categoria
- CEVIU Dados
- Publicado
- 29 de junho de 2026
- Editoria
- CEVIU Dados