Sistemas de produção estão adotando equipes de agentes especializados – como triagem, SQL e Python – e a plataforma MCP surge como integradora, conectando-os a ferramentas como GitHub, Slack e PostgreSQL. Grafos de memória persistente permitem que esses agentes acumulem conhecimento organizacional entre chamadas, otimizando fluxos de trabalho. Contudo, a interação entre múltiplos agentes introduz riscos de 'prompt injection' lateral, o que impulsiona a mitigação com proveniência criptográfica de tooling e o uso de sandboxes efêmeros para garantir a segurança e integridade dos dados e operações.
O PostgreSQL, pilar para muitas startups, frequentemente enfrenta gargalos de escalabilidade decorrentes de falhas operacionais evitáveis. Problemas comuns incluem indexação inadequada, transações excessivamente longas, migrações que travam o sistema, picos de conexão e um autovacuum desatualizado. A solução reside em um design de esquema focado nos padrões de consulta, execução de operações de escrita e migrações de forma não bloqueadora, processamento de grandes volumes de dados em lotes e monitoramento proativo de planos de consulta e a fragmentação do banco de dados (bloat) para evitar interrupções no serviço. Tais práticas são cruciais para a sustentabilidade e crescimento de qualquer startup.
Benchmarks de Text-to-SQL frequentemente superestimam o desempenho real, pois não conseguem replicar a complexidade inerente e a desorganização dos data warehouses modernos. A discrepância entre o ambiente controlado dos testes e a realidade dos dados corporativos, marcados por estruturas heterogêneas e falta de padronização, levanta sérias questões sobre a aplicabilidade prática e a confiabilidade dessas ferramentas em cenários de produção. Entender essa lacuna é crucial para o desenvolvimento de soluções mais robustas e realistas no campo da análise de dados.
A extensão Iceberg do DuckDB agora eleva o nível, permitindo operações CTAS, MERGE INTO, INSERT, UPDATE e DELETE. Isso o estabelece como uma ferramenta robusta para ETL no estilo CRUD (Create, Read, Update, Delete) diretamente em ambientes locais, eliminando a dependência do Apache Spark. Em conjunto com o MinIO para armazenamento compatível com S3 e o LakeKeeper, um catálogo Iceberg baseado em Rust, equipes de engenharia de dados podem prototipar e testar pipelines de forma econômica via Docker, garantindo uma transição fluida para tabelas AWS S3 apenas ajustando variáveis de ambiente e segredos.
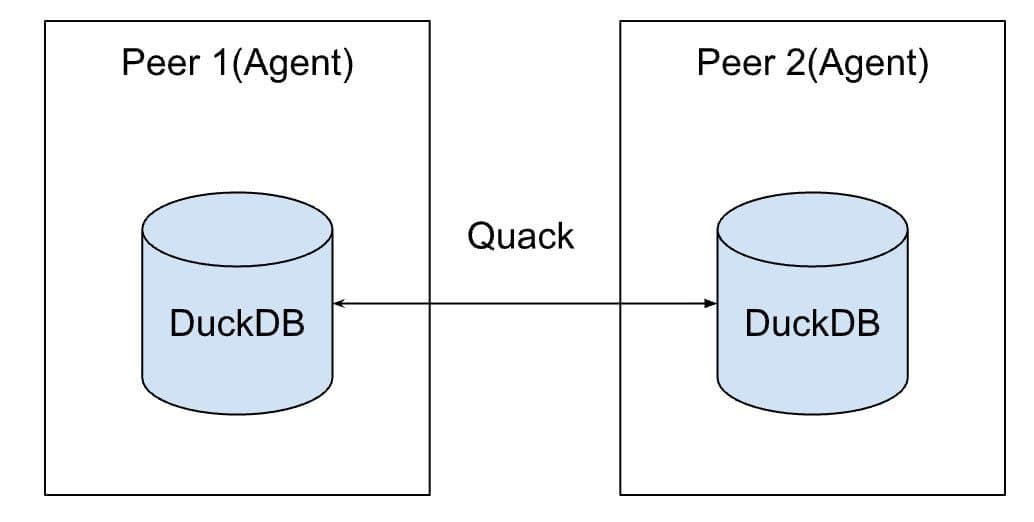
Em sistemas multi-agente, a gestão de dados foi aprimorada ao atribuir a cada agente uma instância local do DuckDB. Para garantir a integridade, a abordagem substitui a troca de snapshots mutáveis por objetos SliceRef imutáveis, que encapsulam um ID de snapshot e um digest de conteúdo, eliminando problemas de coerência de cache. Contratos semânticos, formalizados em Malloy, estabelecem consultas que são artefatos verificáveis por máquina. Uma camada de comparação de contratos categoriza as mudanças, como idênticas, aditivas, "breaking" ou não relacionadas, antes de qualquer processamento subsequente, assegurando a rastreabilidade e a robustez dos dados distribuídos.
A estratégia de backfilling, essencial para o reprocessamento de dados históricos, deve ser integrada ao pipeline de produção para cargas incrementais. Ao invés de scripts isolados, a configuração do pipeline deve permitir processar dados novos, todos os dados ou registros específicos. Esta abordagem, combinada com escritas bitemporais, assegura que o reprocessamento seja seguro, repetível e elimine a fragilidade de soluções ad-hoc.
Uma nova solução de análise de impacto de deriva de esquema para lakehouses surge, utilizando Iceberg e Lakekeeper para transformar alterações de schema em alertas e recomendações quase em tempo real. O processo se inicia com engines de consulta emitindo comandos DDL, que o Lakekeeper prontamente utiliza para atualizar o catálogo Iceberg e disparar eventos de mudança para Kafka/Redpanda. Em questão de segundos, um serviço baseado em FastAPI, aiokafka e Anthropic (IA) analisa o impacto, eliminando a necessidade de varredura de metadados. Os resultados são então entregues via Slack e persistidos em SQLite, agilizando a governança de dados.
No universo do Apache Spark, a recomputação de Common Table Expressions (CTEs) aninhadas e reutilizadas é um desafio de performance padrão. Para contornar isso, a estratégia ideal é o cache seletivo em pontos de "fan-out", especialmente quando os resultados intermediários são complexos, manejáveis em memória e sujeitos a reutilização frequente. É crucial evitar o cache de conjuntos de dados excessivamente grandes ou triviais, que poderiam sobrecarregar o sistema. A implementação do cache "eager" facilita o monitoramento e materializa cadeias de transformação profundas, prevenindo recomputações desnecessárias e otimizando a utilização de recursos.
A escolha do esquema de banco de dados representa um vetor crítico para a dívida técnica, com decisões de design que, uma vez implementadas, são de difícil reversão e podem acarretar custos operacionais e de manutenção por anos. Aspectos como a definição de chaves primárias, estratégias de particionamento e a escolha de tipos de coluna exigem rigorosos guardrails e validação pré-produção. Ignorar tais precauções transforma o banco de dados em um passivo irreversível, comprometendo a escalabilidade e a performance da infraestrutura de dados.
O DuckDB, um dos motores de banco de dados mais eficientes, alcança sua notável velocidade através de uma execução vetorizada que processa dados em lotes otimizados para cache. Em vez de operar linha por linha, ele utiliza blocos de 2.048 linhas, minimizando o overhead. Formatos de vetor, vetores de seleção, operações pré-compiladas e pipelines push-based são elementos-chave que reduzem a cópia de dados, o custo de chamadas de função e os gastos associados à execução paralela, garantindo um desempenho robusto em ambientes analíticos.
A plataforma interna de processamento de conteúdo da Dropbox, Riviera, que já gerencia centenas de milhares de transformações por segundo, evoluiu para integrar capacidades de IA. Seu design modular, baseado em plug-ins, permite a fácil adição de novos formatos de arquivo, o que significa que avanços na extração de texto são instantaneamente aplicados em pré-visualizações, funcionalidades de busca e na preparação de documentos para uso em sistemas de IA. Este aprimoramento sublinha a estratégia da empresa em otimizar a infraestrutura de dados para aplicações inteligentes.
O Apache DataFusion agora implementa uma otimização significativa para o processamento de dados quase ordenados, impactando diretamente operações como `ORDER BY` e `ORDER BY ... LIMIT N`. A ferramenta passa a utilizar automaticamente a ordenação exata e parcial dos dados, empregando estatísticas de min/max do formato Parquet, estratégias de reordenação de arquivos e filtros dinâmicos. Essa abordagem evita varreduras completas e bloqueios de ordenação, resultando em um ganho notável de eficiência para o processamento analítico e de dados em larga escala.
O Aurora DSQL surge como uma solução inovadora para sistemas OLTP (Online Transaction Processing) multi-região, operando em modo ativo-ativo e oferecendo compatibilidade plena com PostgreSQL, além de consistência forte. A plataforma simplifica a gestão de infraestrutura ao eliminar a necessidade de gerenciar servidores, shards, réplicas e failover. Embora a latência cross-region seja compensada no commit, equipes de dados devem atentar para a execução de transações curtas e considerar limitações atuais, como o limite de 3.000 linhas ou 10 MiB por transação e a ausência de chaves estrangeiras impostas.
No recente evento VB Transform 2026, empresas como LinkedIn, Walmart e Zendesk compartilharam suas abordagens inovadoras para superar os desafios da infraestrutura legada frente à velocidade dos agentes de IA. O LinkedIn destacou a importância de pré-provisionar containers e a transição de 80% da orquestração para código determinístico. Já o Walmart focou na governança de agentes internos duplicados, enquanto a Zendesk aprimorou seus pipelines de dados para processar um volume massivo de 20 bilhões de conversas. As lições aprendidas apontam para a necessidade de avaliações contínuas, controle sobre o 'agent harness' e a portabilidade das cargas de trabalho entre diferentes modelos.
A Meta está aprimorando a otimização de seu funil de anúncios por meio de uma abordagem inovadora: a compressão de bilhões de usuários e entidades em clusters de interesses latentes. Estes são enriquecidos com conteúdo de anúncios processado por Large Language Models (LLMs), incorporando tudo em um espaço compartilhado para pontuar qualquer usuário ou entidade. Ao aprender com a estrutura ampla do grafo, e não apenas com eventos de conversão raros, a Meta obtém um sinal robusto para o funil profundo, alimentando modelos de ranking de anúncios como GEM e Andromeda. Essa estratégia promete maior precisão e relevância em suas campanhas.
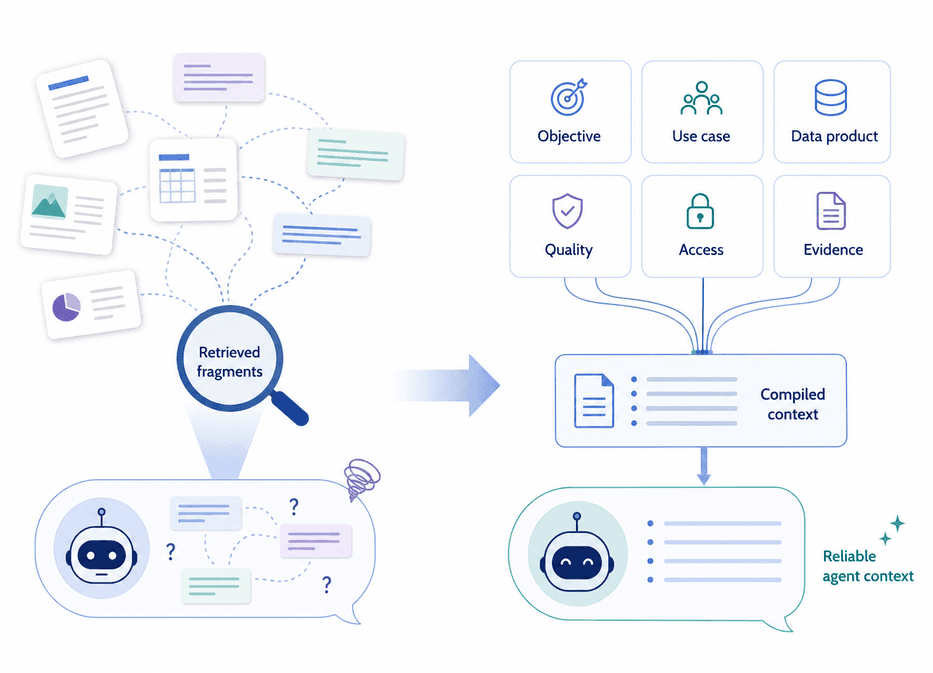
Para agentes de IA empresariais, a busca por vetores e o Retrieval Augmented Generation (RAG) não são suficientes. Embora o RAG consiga identificar passagens relevantes, ele não garante a preservação de limites de origem, o significado de negócio, a propriedade ou as restrições de uso dos dados. A solução proposta foca na construção de um modelo de produto de dados governado, compilado em diversas representações, como grafos, wikis Markdown, pacotes OKF e sidecars compactos (TOON/GCF). Isso demonstra que a preparação para a IA não se resume a um catálogo, mas sim a um contexto conectado, confiável e a operações repetíveis, garantindo que a IA opere com dados estruturados e bem definidos.
O Apache Spark 4.2 acaba de ser lançado, apresentando uma série de melhorias que reforçam sua posição como ferramenta central no processamento de dados. Entre as novidades, destacam-se as "metric views" para a definição de métricas de negócio, a busca de similaridade via SQL vector e a introdução de tipos geoespaciais nativos. A versão também incorpora queries de Change Data Capture (CDC) através da nova cláusula CHANGES, otimizando a sincronização de dados. A facilidade de uso foi aprimorada com o Spark Connect e a execução padrão otimizada com Arrow para Python. Com mais de 1.900 commits de 260 contribuidores, o Spark 4.2 promete maior eficiência e flexibilidade para o ecossistema de dados.
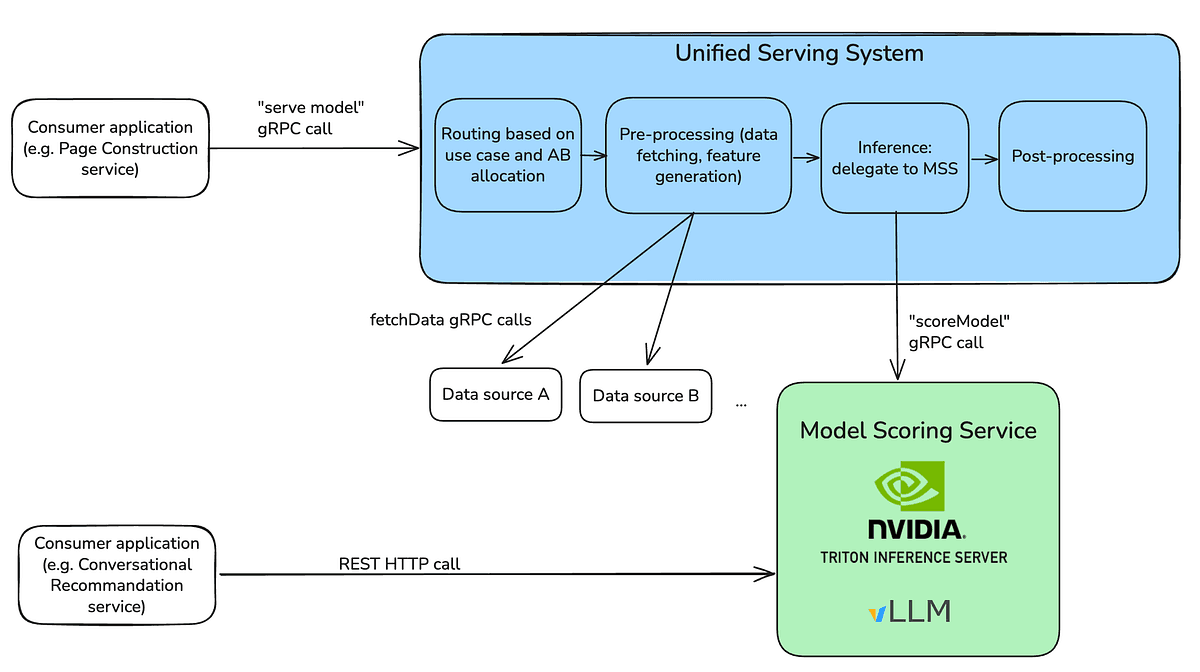
A Netflix implementou uma plataforma unificada para operar seus serviços de LLMs internamente, evitando APIs externas. A arquitetura, baseada em JVM com gRPC e uma API HTTP compatível com OpenAI, padroniza a implantação via Model Scoring Service. Este serviço é suportado pelo Triton e utiliza o vLLM como motor principal, após rigorosos testes de benchmark. A solução ainda inclui empacotamento customizado, atualizações sem interrupção e decodificação guiada, com patches específicos para garantir a correta geração de saídas JSON, otimizando performance e controle da IA.
O Apache DataFusion Comet eleva o desempenho de leitura do Spark em tabelas Iceberg, combinando o planejamento de queries em Java com a execução nativa Arrow via Iceberg Rust. Testes de benchmark TPC-DS de 3 TB demonstraram um salto significativo: 102 de 103 queries aceleradas e uma redução de aproximadamente 40% no tempo total de execução. Adicionalmente, a interoperabilidade com os pacotes de testes Spark do Iceberg Java foi crucial, impulsionando mais de 40 pull requests que aprimoraram o Iceberg Rust.
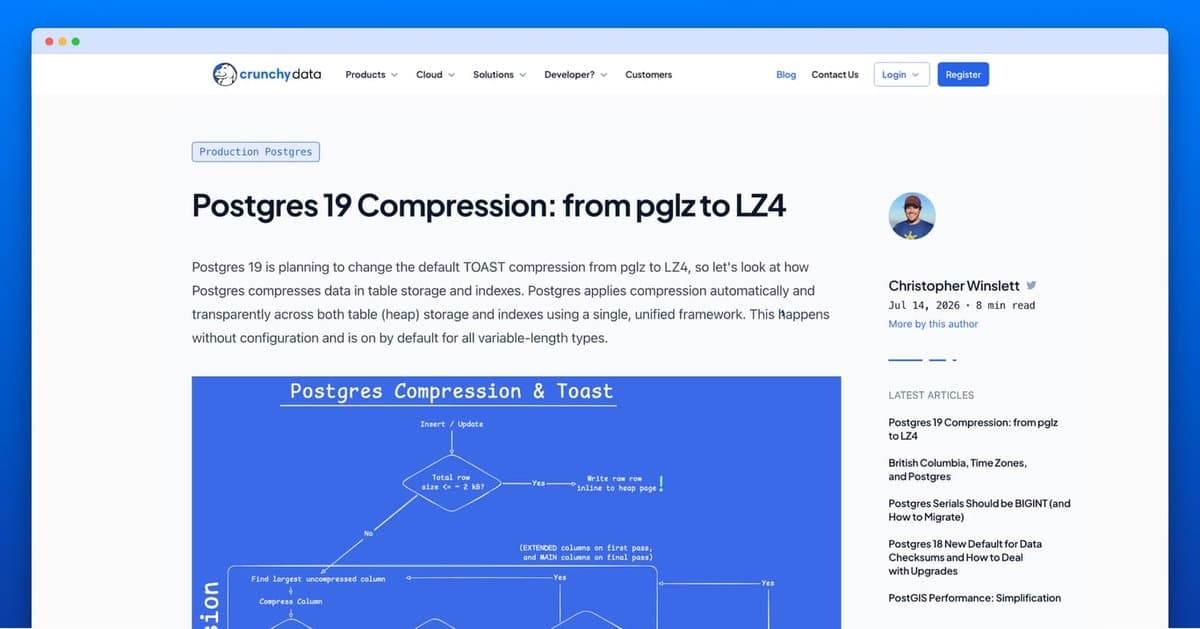
O vindouro Postgres 19 trará uma importante otimização na gestão de armazenamento, substituindo a compressão padrão de objetos TOAST do algoritmo pglz para o LZ4. Esta mudança, que será integrada ao framework unificado de compressão, abrange não apenas o armazenamento em heap, mas também TOAST e índices B-tree. Tipos de dados de comprimento variável como TEXT, VARCHAR, BYTEA e JSONB, que superam o limite de aproximadamente 2 KB, serão automaticamente beneficiados. Testes preliminares apontam que o LZ4 oferece desempenho superior ao pglz, garantindo compressão mais eficiente e detecção rápida de dados incompressíveis, resultando em maior eficiência e menor latência para operações de banco de dados.