Como a OpenAI entrega voz com baixa latência para 900 milhões de usuários
Aprofundamento CEVIU
Aprofundamento
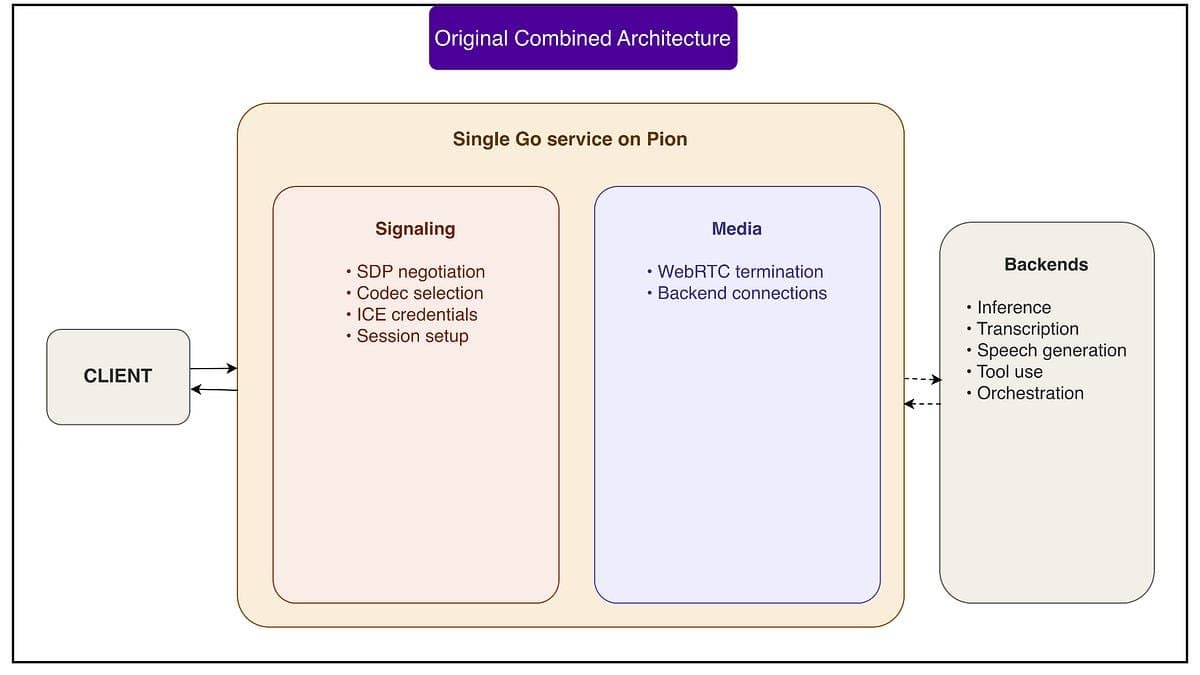
A OpenAI não está só escalando voz: está redefinindo o que é possível em tempo real para IA falada. O segredo não está no modelo, mas na camada de rede que o sustenta. Enquanto a maioria das empresas ainda luta com pipelines STT → LLM → TTS (que somam facilmente 1,5 s de latência), a infraestrutura descrita em maio de 2026 entrega 800 ms fim a fim em redes móveis, e 300 ms só na etapa crítica de endpointing (detecção de início/fim de fala). Isso só funciona porque o WebRTC deixou de ser um protocolo genérico e virou uma peça de engenharia personalizada: o ufrag, campo originalmente usado só para identificação de sessão, agora carrega metadados de roteamento codificados; o relay em Go não faz parsing de pacotes inteiros, só do cabeçalho STUN necessário; e cada transceiver usa SO_REUSEPORT + LockOSThread para garantir que fluxos de áudio sejam processados no mesmo core, sem saltos de cache ou jitter.
O timing é estratégico: essa infraestrutura foi lançada junto com o GPT-Realtime-2, modelo speech-to-speech nativo que opera diretamente no domínio do áudio, sem conversões intermediárias. Não é só mais rápido. É outro paradigma: entonação, pausas e até microexpressões vocais são preservadas porque o modelo ‘ouve’ e ‘fala’ no mesmo fluxo contínuo, não em blocos discretos.
O que mudou
Em fevereiro de 2026, a Realtime API usava um único serviço Go em Pion, com WebRTC rodando monoliticamente, funcional, mas frágil em Kubernetes. Em maio, a arquitetura split relay+transceiver já estava em produção global, com Global Relay distribuído via Cloudflare e Redis como cache de rota. Agora, em julho de 2026, a OpenAI confirma que esse stack suporta 900 milhões de usuários semanais, número que era apenas uma meta anunciada em março. O que era teórico (roteamento por ufrag) virou métrica operacional: 97% das sessões estabelecem conexão em ≤250 ms, e falhas por migração de pod caíram 92% após a adoção do estado leve no relay.
Por que isso importa
Voz com latência sub-800 ms não é só 'mais rápida'. É o limiar entre interação e interrupção: acima disso, usuários cortam a IA no meio da frase. Abaixo, a conversa flui como humano, e isso muda o uso prático. Call centers já testam agentes que negociam contratos em tempo real sem gravações pós-processadas. Aplicativos médicos usam o mesmo stack para triagem vocal com detecção de tremor ou fadiga na voz. A infraestrutura não é um detalhe técnico: é o que permite levar IA falada para o mundo real, não só para demos.
Linha do tempo
Lançamento da Realtime API com gpt-realtime e guia de prompting para voz
Introdução do modo WebSocket para reduzir latência em agentes de IA
Rearquitetura WebRTC com modelo split relay+transceiver entra em produção
Lançamento do GPT-Realtime-2, modelo speech-to-speech nativo integrado à nova infraestrutura
Confirmação de escala para 900 milhões de usuários semanais com latência média de 800 ms fim a fim
Perguntas frequentes
Por que a OpenAI não usou um SFU como outras plataformas de videoconferência?
SFUs são ótimos para multiparty (ex: Zoom), mas adicionam overhead desnecessário em 1:1 humano-IA. A OpenAI precisava de baixa latência, não de mixagem de streams. Um SFU forçaria o modelo a se comportar como um participante WebRTC, com handshakes extras e gerenciamento de estado redundante.
O que torna o ufrag um bom campo para roteamento, e não outra parte do pacote?
É um campo obrigatório no handshake ICE, presente desde o primeiro STUN binding request. Não exige novos round-trips, não depende de serviços externos e já é processado pelo cliente, então o relay pode ler e encaminhar na primeira chegada, sem alterar o comportamento do protocolo.
Como o Go consegue lidar com milhares de sessões UDP sem kernel bypass?
Com três otimizações combinadas: SO_REUSEPORT distribui pacotes entre workers; LockOSThread fixa goroutines em cores específicas para evitar cache misses; e parsing de baixa alocação reduz pressão no garbage collector, eliminando picos de latência causados por coleta de lixo.
Essa infraestrutura serve só para ChatGPT Voice ou também para APIs terceiras?
Serve ambos. A Realtime API pública usa exatamente o mesmo stack, inclusive o GPT-Realtime-2 e os endpoints de tradução simultânea. Desenvolvedores que integram a API herdam automaticamente as otimizações de roteamento geográfico e endpointing em tempo real.
Fontes
- blog.bytebytego.comfonte original
- Categoria
- CEVIU IA
- Publicado
- 03 de julho de 2026
- Editoria
- CEVIU IA