Como a OpenAI gerencia IA de voz com baixa latência para 900 milhões de usuários
Aprofundamento CEVIU
Aprofundamento
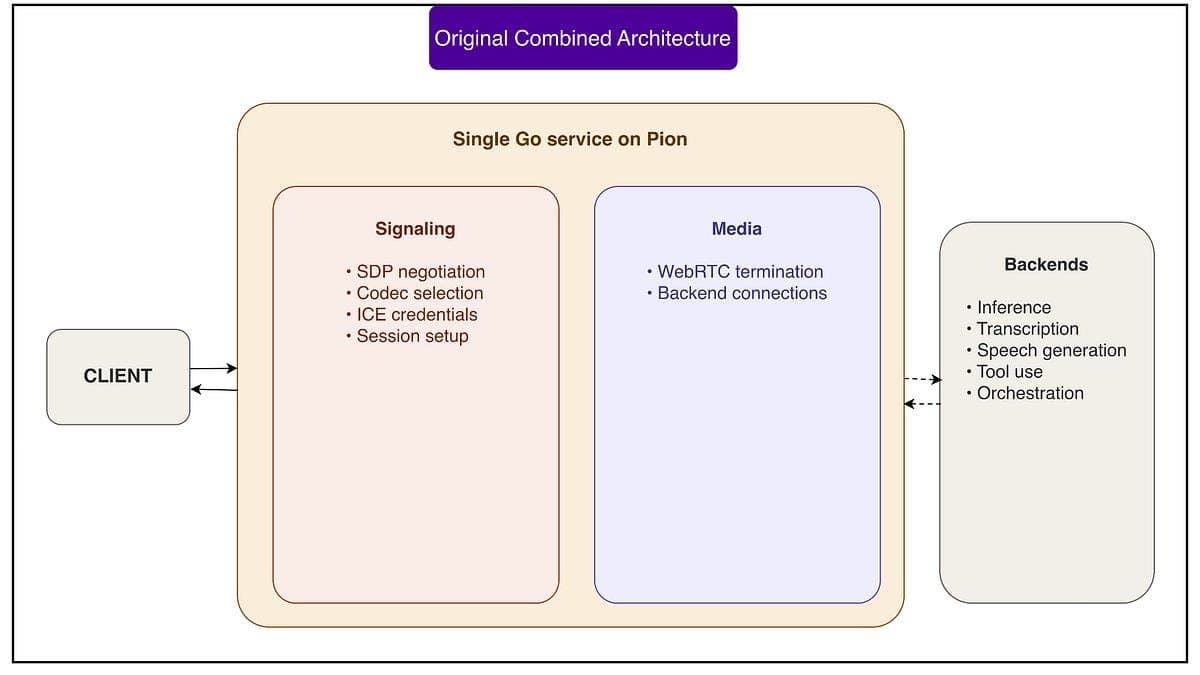
A OpenAI não só adotou o modelo split relay + transceiver, ela o aprimorou com decisões de engenharia que impactam diretamente a experiência do desenvolvedor (DX) e a performance em produção. A escolha de usar SO_REUSEPORT em vez de kernel bypass mostra uma priorização clara: evitar complexidade operacional sem sacrificar throughput. Isso é crítico para equipes que mantêm serviços em Go em Kubernetes, onde cada dependência externa aumenta o custo de observabilidade e rollout. O uso de runtime.LockOSThread não é só otimização de cache, é uma forma de garantir previsibilidade em ambientes com alta concorrência de UDP, evitando jitter que quebraria a fluidez da fala para fala.
O detalhe técnico mais relevante para devs de infra e backend é como a OpenAI contorna o limite fundamental do WebRTC: ele foi feito para descartar pacotes, não para entregar áudio PCM bruto com precisão. Ao manter o transceiver como ponto único de terminação de DTLS/SRTP, a IA consegue processar o fluxo cru, essencial para o novo pipeline nativo de voz (fala → fala), que substitui a antiga cadeia STT → LLM → TTS. Isso não é só sobre latência: é sobre eliminar a perda de informação entre estágios, algo que afeta diretamente a qualidade do prompt e a coerência da resposta falada.
O que mudou
A cobertura CEVIU de maio mostrava a arquitetura conceitualmente dividida, relay stateless, transceiver stateful. Agora, com a notícia de 3 de julho, sabemos exatamente como o ufrag codifica metadados de roteamento e como isso elimina consultas a Redis na primeira requisição STUN. Antes era teoria; agora é implementação em produção com fallback automático via Redis cache. Também há confirmação de que o Go userspace relay já está em escala global, com Cloudflare fazendo geo-steering tanto na sinalização quanto no media path, um nível de integração que não estava claro nos relatos iniciais.
Por que isso importa
Essa arquitetura não é só para a OpenAI: ela redefine o que é viável com WebRTC em backends de IA. Desenvolvedores que tentam construir voice agents com baixa latência agora têm um blueprint validado para evitar os dois erros mais comuns: usar SFU como se fosse um proxy genérico (e perder acesso ao áudio bruto) ou tentar rodar WebRTC inteiro em um único serviço sob Kubernetes (e bater em port exhaustion e state stickiness). A lição prática é clara: se seu caso é 1:1 voz-IA, não force o SFU. Invista em separar roteamento (stateless, leve, geodistribuído) de estado (stateful, com controle total sobre codecs, SRTP e DTLS).
Linha do tempo
CEVIU publica primeira análise da arquitetura split relay + transceiver da OpenAI
CEVIU detalha a separação entre roteamento de pacotes e terminação de protocolo
CEVIU compara a abordagem da OpenAI com o Inference Router da DigitalOcean
OpenAI revela implementação concreta com ufrag como chave de roteamento e otimizações em Go
Perguntas frequentes
Por que a OpenAI não usa um SFU como outras plataformas de videoconferência?
Porque o SFU encaminha streams criptografados, mas a IA precisa do áudio PCM decodificado em tempo real para inferência. Um SFU forçaria a IA a se comportar como um peer WebRTC, adicionando latência e complexidade desnecessária. O transceiver permite que a IA processe o áudio cru diretamente.
O que é ufrag e por que codificar nele dados de roteamento é uma boa ideia?
ufrag é um campo obrigatório do ICE usado em STUN binding requests. Como ele já é trocado no primeiro pacote da sessão, usar seu valor como chave de roteamento evita consultas externas (como bancos de dados) na hot path. É reuso inteligente de um campo existente, não uma extensão do protocolo.
Como o SO_REUSEPORT resolve o problema de port exhaustion no Kubernetes?
Ele permite que múltiplos processos Go (workers) compartilhem a mesma porta UDP. O kernel distribui os pacotes entre eles automaticamente. Assim, não é preciso reservar milhares de portas distintas, basta uma única porta por pod, escalável horizontalmente.
Por que a OpenAI optou por Go em userspace em vez de frameworks de kernel bypass?
Kernel bypass (como DPDK ou XDP) aumenta throughput, mas também a complexidade operacional, depuração e integração com Kubernetes. A equipe concluiu que otimizações em Go, SO_REUSEPORT, LockOSThread, buffers pré-alocados, atingem o desempenho necessário sem comprometer a manutenibilidade.
Fontes
- blog.bytebytego.comfonte original
- Categoria
- CEVIU Web Dev
- Publicado
- 03 de julho de 2026
- Editoria
- CEVIU Web Dev