Benchmarking de modelos agentic com seu próprio ecossistema de ferramentas
Aprofundamento CEVIU
Aprofundamento
O benchmarking de modelos agentic com ecossistemas de ferramentas personalizados deixou de ser um exercício teórico e virou uma prioridade operacional para time de engenharia de bibliotecas como transformers, LangChain e Google ADK. Diferente de benchmarks tradicionais que só verificam o resultado final, essa nova geração de avaliação mede a trajetória completa: quantos tokens o agente usou, quantas chamadas de ferramenta fez, se invocou APIs depreciadas, quantos erros de tipo ou shape ele gerou, e se conseguiu se recuperar sozinho. O artigo original mostra isso em prática com transformers, mas a pesquisa web confirma que o mesmo padrão já está sendo aplicado em produção por times da Mercor (com APEX-Agents), Hugging Face (via Jobs paralelos) e BenchLM.ai, que rastreia 26 benchmarks agênticos em tempo real.
Modelos como GPT-5.5 Pro, Gemini 3 Flash e Holo3-35B-A3B são agora comparados não só por acurácia, mas por eficiência de execução: latência média por tarefa, taxa de falha em chamadas de ferramenta e número médio de iterações até o sucesso. O AgentRace (lançado em dezembro de 2025) e o MultiAgentBench (março de 2025) validam que frameworks como Autogen, CrewAI e LangGraph têm perfis distintos nesses indicadores, o que torna essencial testar o agente *no seu próprio stack*, não em ambientes genéricos.
Por que isso importa
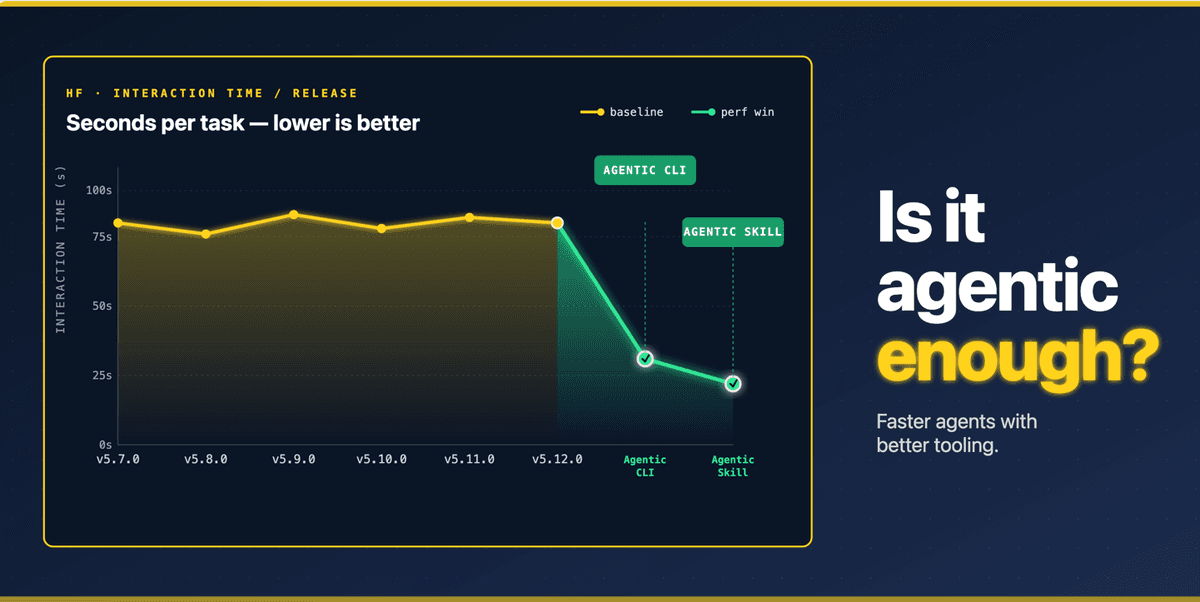
Porque avaliar apenas se o agente 'acertou' esconde problemas críticos de custo, segurança e manutenção. Um agente que resolve uma tarefa de classificação de sentimentos com 40 linhas de código, dois retries e uso de uma API obsoleta pode ter 100% de match %, mas custa 3× mais em tokens, demora 5× mais e abre superfícies de ataque como injeção indireta de prompt. O artigo original mostra isso com clareza: melhorias como CLI agent-optimized no transformers reduziram uso de tokens entre 1,3× e 6×. Isso não é só otimização, é exigência para produção. Relatórios recentes da McKinsey e dados do APEX-Agents confirmam: mais de 70% das tarefas profissionais (consultoria, advocacia, análise financeira) ainda falham em ambientes reais, não por falta de raciocínio, mas por mau alinhamento entre o modelo, as ferramentas e os fluxos de trabalho.
Impacto para desenvolvedores
Desenvolvedores de bibliotecas precisam agora pensar em três coisas ao mesmo tempo: documentação estruturada para agentes (não só para humanos), APIs previsíveis com mensagens de erro úteis para LLMs e exemplos curtos, autocontidos e executáveis, como os 'skills' citados no artigo. Se seu pacote não tem CLI ou interface de linha de comando bem projetada, agentes vão contorná-la com código imperativo, aumentando custo e risco. Ferramentas como o harness descrito, rodando em Hugging Face Jobs com isolamento de hardware, já estão disponíveis como referência. E frameworks como AgentRace e MARL-EVAL oferecem métricas prontas para integrar em pipelines CI/CD, transformando 'teste de agente' em etapa obrigatória de release, assim como testes unitários.
Perguntas frequentes
O que é benchmarking agêntico com ecossistema de ferramentas?
É uma metodologia de avaliação que mede não só se um agente de IA resolveu uma tarefa, mas como ele fez isso: quantas chamadas de ferramenta usou, se escolheu APIs corretas, quantos erros gerou e quantos tokens consumiu. Diferente de benchmarks de LLMs tradicionais, foca na trajetória completa de execução em ambientes controlados com ferramentas personalizadas.
Quais são os principais benchmarks agênticos em 2026?
Em junho de 2026, os principais benchmarks incluem AgentRace (focado em latência e comunicação entre frameworks), MultiAgentBench (para sistemas multiagentes), MARL-EVAL (aprendizado por reforço multiagente) e APEX-Agents (desempenho em tarefas profissionais). BenchLM.ai rastreia 26 desses benchmarks, com GPT-5.5 Pro liderando a categoria agêntica com 90.1 pontos.
GPT-5.5 Pro, GPT-5.2 e Gemini 3 Flash são modelos agênticos?
Sim. O GPT-5.5 Pro é o modelo agêntico mais bem avaliado segundo BenchLM.ai (junho de 2026), com pontuação verificada de 90.1. O GPT-5.2 e o Gemini 3 Flash também foram testados no APEX-Agents: o primeiro obteve 27,3% em tarefas de analistas de investimentos; o segundo, 25,9% em tarefas jurídicas. Nenhum desses modelos foi lançado como 'GPT-6' ou 'GPT-5.6', termos que ainda não aparecem em fontes confiáveis.
Como testar meu próprio agente com ferramentas personalizadas?
Você pode usar o harness descrito no artigo original, um ambiente open source que roda tarefas em Hugging Face Jobs com hardware idêntico, medindo match %, token usage, iterações e tempo. Alternativas práticas incluem integrar AgentRace para benchmarks de desempenho ou adaptar o MultiAgentBench para cenários interativos. O essencial é testar com seu ecossistema real, não com mockups.
Fontes
- huggingface.cofonte original
- Categoria
- CEVIU IA
- Publicado
- 18 de junho de 2026
- Editoria
- CEVIU IA