Cursor lança o CursorBench 3.1 para testar o limite de agentes de IA em codificação complexa
O Cursor anunciou o lançamento do CursorBench 3.1, um benchmark projetado para avaliar o desempenho de agentes de IA em tarefas de codificação complexas e ambíguas. Diferente de testes sintéticos, ele se baseia em sessões reais de uso da própria ferramenta de desenvolvimento, exigindo que os modelos editem múltiplos arquivos simultaneamente. A novidade visa elevar a barra de avaliação da engenharia de software autônoma.
Aprofundamento CEVIU
Aprofundamento
O CursorBench é um benchmark criado pela Cursor para medir o desempenho real de agentes de IA em tarefas de engenharia de software que exigem compreensão de códigobase, planejamento multi-etapa e edição simultânea em vários arquivos, não apenas correção pontual ou autocomplete. A versão 3.1, lançada em 3 de julho de 2026, introduz problemas baseados em sessões reais de uso da plataforma, com foco explícito em detecção de bugs, revisão de código e tomada de decisão técnica ambígua. Diferente de benchmarks sintéticos como HumanEval ou MBPP, o CursorBench não testa capacidade de gerar código isolado, mas sim a habilidade do agente de navegar contexto complexo, manter estado entre etapas e justificar escolhas, algo crítico para agentes que operam em ambientes corporativos reais.
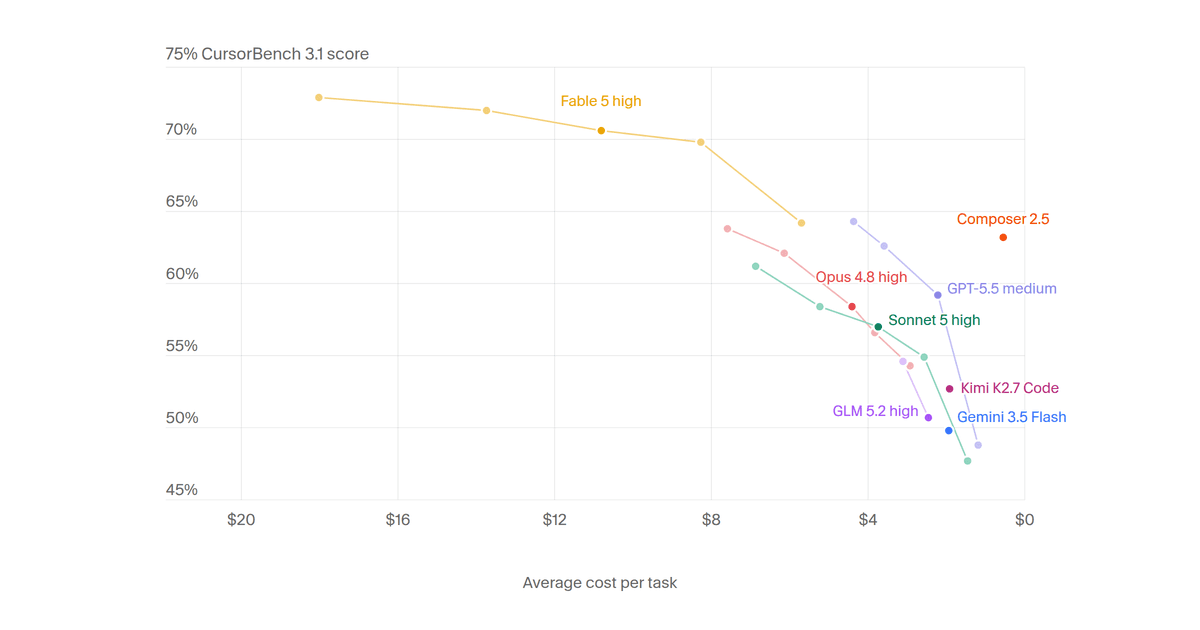
Os resultados são divulgados com métricas cruzadas: taxa de sucesso por tarefa, custo médio (em dólares e tokens) e número de passos executados. Isso revela trade-offs reais, por exemplo, modelos como Opus 4.8 Extra High atingem 75% de acerto, mas com custo médio de $16 por tarefa; já o Composer 2.5 alcança 60%, com custo de $4. O artigo-fonte Cursor.com/evals não revela detalhes de infraestrutura de avaliação nem metodologia de anotação humana, mantendo opaca a curva de graduação subjetiva em tarefas de revisão ou planejamento.
O que mudou
A mudança real entre as versões anteriores e a 3.1 está na natureza das tarefas: a 3.0, lançada antes de abril de 2026, focava em edições, refatorações e correções pontuais. A 3.1 expande para quatro dimensões novas, compreensão de códigobase, busca de bugs, planejamento estratégico e revisão crítica, todas extraídas de sessões reais do Cursor 3, plataforma lançada em abril. Isso alinha o benchmark diretamente ao novo modelo Fable 5 (1,5 trilhão de parâmetros) e ao Composer 2.5, ambos treinados com dados sintéticos e reforço direcionado para esse tipo de comportamento agentic. Antes era teste de execução. Agora é teste de raciocínio técnico aplicado.
Por que isso importa
CursorBench 3.1 muda o jogo porque impõe uma nova barra de validação para agentes de codificação: não basta gerar código funcional, é preciso entender intenção, equilibrar trade-offs e justificar decisões, habilidades que definem se um agente pode substituir ou ampliar o papel de um engenheiro sênior. Isso força provedores a priorizarem arquiteturas com memória de longo prazo, ferramentas de introspecção de códigobase e loops de validação interna. Para empresas, o benchmark oferece um critério objetivo para comparar custo-benefício entre modelos como Opus, Sonnet e Fable, especialmente relevante após o lançamento do Fable 5, treinado em 100.000 GPUs, e do Composer 2.5, otimizado para eficiência em tarefas contínuas.
Linha do tempo
Cursor expande acesso à prévia de agentes de longa duração
Lançamento do Cursor 3, workspace unificado para agentes
Atualização da plataforma Cursor com foco em agentes de IA
Lançamento do Composer 2.5 com reforço e dados sintéticos
Lançamento do modelo Fable 5 com 1,5 trilhão de parâmetros
Lançamento do ScarfBench para migração de frameworks Java
Lançamento do CursorBench 3.1 para avaliação de agentes em tarefas complexas
Perguntas frequentes
CursorBench 3.1 é aberto? Posso rodá-lo localmente?
Não há indicação de que o CursorBench 3.1 seja open source ou disponibilizado como repositório público. A página oficial [[LINK:source_article|cursor.com/evals]] mostra apenas resultados agregados e gráficos. Não há link para download de tasks, scripts de avaliação ou documentação técnica de implementação.
Como o CursorBench 3.1 difere do ScarfBench lançado dois dias antes?
O ScarfBench avalia agentes exclusivamente em migração de frameworks Java corporativos, um cenário vertical e altamente especializado. Já o CursorBench 3.1 é horizontal: testa competências transversais (planejamento, revisão, bugfinding) em múltiplos stacks, com tarefas extraídas de uso real da plataforma Cursor. São benchmarks complementares, não concorrentes.
Por que o custo por tarefa varia tanto entre modelos?
O custo reflete o total de tokens processados (input, cache read/write, output) multiplicado pelas tarifas publicadas de cada modelo. Modelos mais precisos como Opus 4.8 Extra High usam mais passos e tokens para validar hipóteses, o que eleva o custo. Já o Composer 2.5 foi otimizado para eficiência, reduzindo iterações sem sacrificar muito acurácia.
O CursorBench 3.1 substitui benchmarks anteriores como HumanEval?
Não. Ele não mede geração de código a partir de docstrings, como HumanEval. É um benchmark complementar, voltado especificamente para avaliação de agentes que operam em IDEs reais, com capacidade de navegação, edição multi-arquivo e tomada de decisão iterativa. Serve a um propósito distinto.
Fontes
- cursor.comfonte original
- Categoria
- CEVIU IA
- Publicado
- 03 de julho de 2026
- Editoria
- CEVIU IA