Processamento de dados migra da CPU para a GPU: novos pipelines exigem arquitetura híbrida
Aprofundamento CEVIU
Aprofundamento
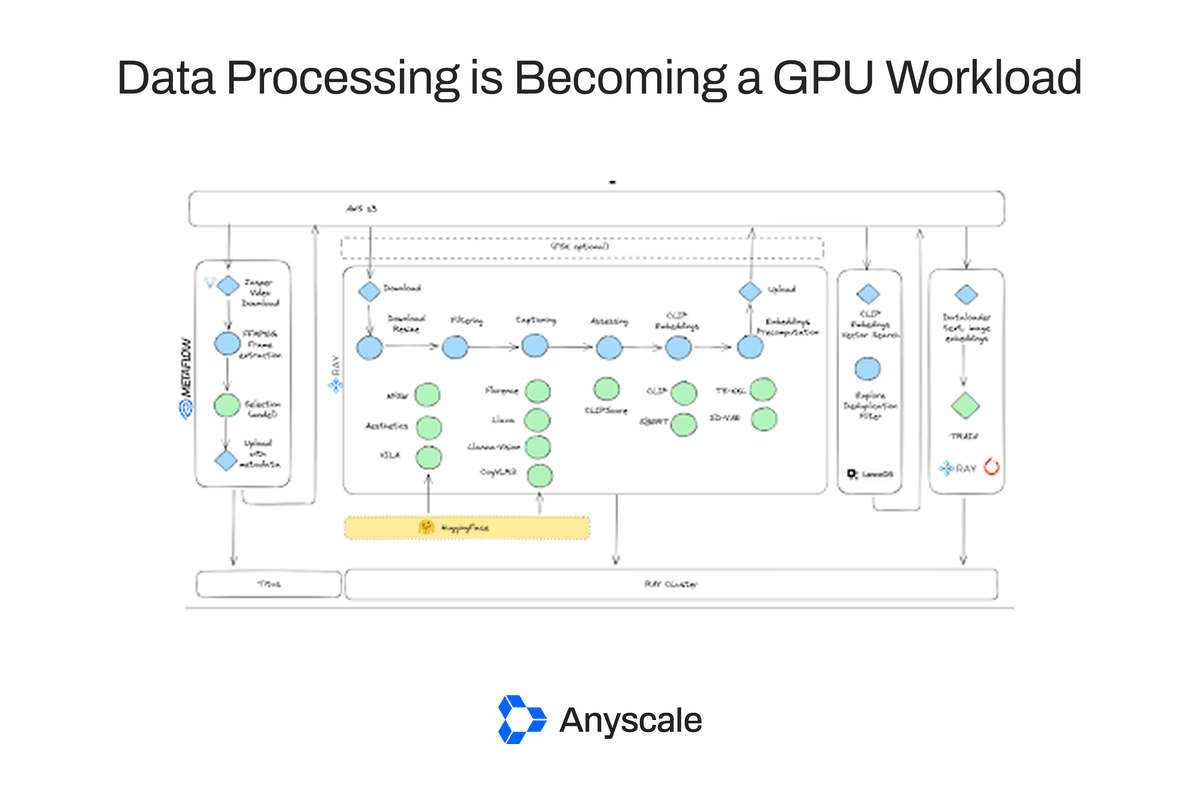
O processamento de dados não está só migrando para a GPU: está se redefinindo como um ciclo contínuo entre inferência e estruturação. Dados multimodais, vídeos, áudio, PDFs, logs do Slack, sensores, não são mais ‘armazenados e ignorados’. Eles entram em pipelines onde modelos geram embeddings, rótulos e resumos em tempo real, criando a estrutura que alimenta SQL, RAG e buscadores vetoriais. Isso exige arquiteturas híbridas não por conveniência, mas por necessidade técnica: pré-processamento em CPU, inferência em GPU, pós-processamento em CPU e orquestração via API, tudo concorrente, com backpressure e streaming nativo. O mercado reflete essa virada: o segmento de GPUs para data centers deve saltar de US$ 21,77 bi (2025) para US$ 226,87 bi até 2035, com CAGR de 26,41%. A NVIDIA Blackwell e a AMD MI325X não são upgrades incrementais, são plataformas projetadas para esse novo workload, onde a unidade de processamento já não é o dado, mas a inferência.
Essa mudança também redefine o papel dos bancos de dados. Eles deixam de ser repositórios passivos para atuar como camadas ativas de IA: suportam busca vetorial com latência submilissegundo, servem embeddings diretamente para agentes e integram-se a orquestradores como Ray ou LangChain. Não basta ter um vector DB, ele precisa operar como parte de um pipeline heterogêneo, com I/O via API, não via arquivo ou JDBC. É nesse ponto que a ‘pipeline tax’ aparece: cada salto entre warehouse, lakehouse, RAG e vector DB acrescenta latência e risco de desvio de governança, como já alertado na cobertura CEVIU de 21/05.
O que mudou
A cobertura CEVIU de 07/04 já antecipava que bancos de dados estavam se tornando ferramentas ativas de IA. Agora, com a migração efetiva de etapas críticas para GPU, essa ativação deixou de ser conceitual: é operacional. Em abril, falávamos em ‘busca vetorial’ e ‘agentes’ como tendências. Em junho de 2026, elas exigem hardware dedicado, não apenas software. Também evoluímos da ideia de ‘IA híbrida’ (citada em 04/04) para uma arquitetura concreta: clusters com alocação granular de recursos (CPU-only, GPU-only, CPU+GPU), com sistemas como Ray ou Anyscale gerenciando o fluxo entre estágios, conforme destacado no artigo-fonte. A ‘pipeline tax’, mencionada em 21/05, agora tem um custo mensurável em GPU-hours ociosas, não só em latência.
Por que isso importa
Isso importa porque muda quem controla o valor dos dados. Antes, o valor estava na agregação e no reporting. Hoje, está na capacidade de transformar ruído (um vídeo de reunião, um log de sensor) em sinal estruturado, e isso depende de infraestrutura de inferência otimizada, não de poder de CPU. Empresas que adotarem arquiteturas híbridas com streaming nativo e gestão de APIs integrada ganham vantagem competitiva em velocidade de insight: identificar riscos contratuais em segundos, não em dias; extrair insights de vídeos de clientes em lote, não em amostras manuais. No Brasil, provedores como Skynova já oferecem Cloud GPU soberana, o que significa que a adoção não depende só de orçamento, mas de decisão estratégica de engenharia de dados.
Linha do tempo
CEVIU destaca migração para arquiteturas híbridas e edge impulsionadas por latência, custo e compliance
CEVIU analisa bancos de dados como componentes ativos de IA, com foco em busca vetorial e agentes
CEVIU mostra que Small Language Models reduzem custos de inference em até 90% e redefinem a arquitetura
CEVIU explica que inference exige submilissegundos de latência, vector DBs e armazenamento desacoplado
CEVIU identifica a 'pipeline tax' como obstáculo à escalabilidade de IA empresarial em agentes
Migração efetiva do processamento de dados da CPU para a GPU, com pipelines orientados a inference e arquitetura híbrida como padrão operacional
Perguntas frequentes
Por que não posso simplesmente rodar meus pipelines Spark em GPUs?
Spark foi feito para processamento em lote homogêneo, com barreiras rígidas entre estágios. Pipelines de IA exigem execução simultânea: CPU faz pré-processamento enquanto GPU roda inferência, e ambas precisam se comunicar via API sem materializar dados intermediários. Forçar isso no Spark gera subutilização grave, especialmente das GPUs, que ficam ociosas esperando os estágios CPU terminarem.
Qual é o papel real dos bancos de dados nessa nova arquitetura?
Eles viraram ‘camadas de inferência operacional’: não só armazenam embeddings, mas servem como pontos de entrada para retrieval em tempo real, alimentam agentes com contexto estruturado e integram-se diretamente a orquestradores. Um banco de dados moderno precisa suportar submilissegundos de latência de acesso, concorrência massiva de leitura e escrita via API, não apenas SQL.
O que muda na governança de dados com essa migração?
A governança deixa de focar só em lineage de tabelas e passa a rastrear proveniência de embeddings, versões de modelos usados na curadoria, políticas de rate limiting em APIs externas e auditoria de chamadas a modelos de terceiros. A ‘pipeline tax’ citada em 21/05 mostra que cada salto entre sistemas aumenta o risco de perda de contexto e conformidade, especialmente em setores regulados.
Small Language Models (SLMs) têm algum papel nessa transição?
Têm papel central. Enquanto LLMs pesados rodam em GPUs para tarefas complexas, SLMs especializados (como os citados em 05/05) operam em CPUs ou NPUs locais para pré-filtragem, rotulação inicial e validação rápida, reduzindo até 90% do tráfego que chega às GPUs. Isso torna a arquitetura híbrida não só viável, mas economicamente obrigatória.
Fontes
- anyscale.comfonte original
- Categoria
- CEVIU Dados
- Publicado
- 18 de junho de 2026
- Editoria
- CEVIU Dados