Data 360 da Salesforce processa 1 quatrilhão de registros/mês com arquitetura flexível, mas metadados viraram gargalo
Aprofundamento CEVIU
Aprofundamento
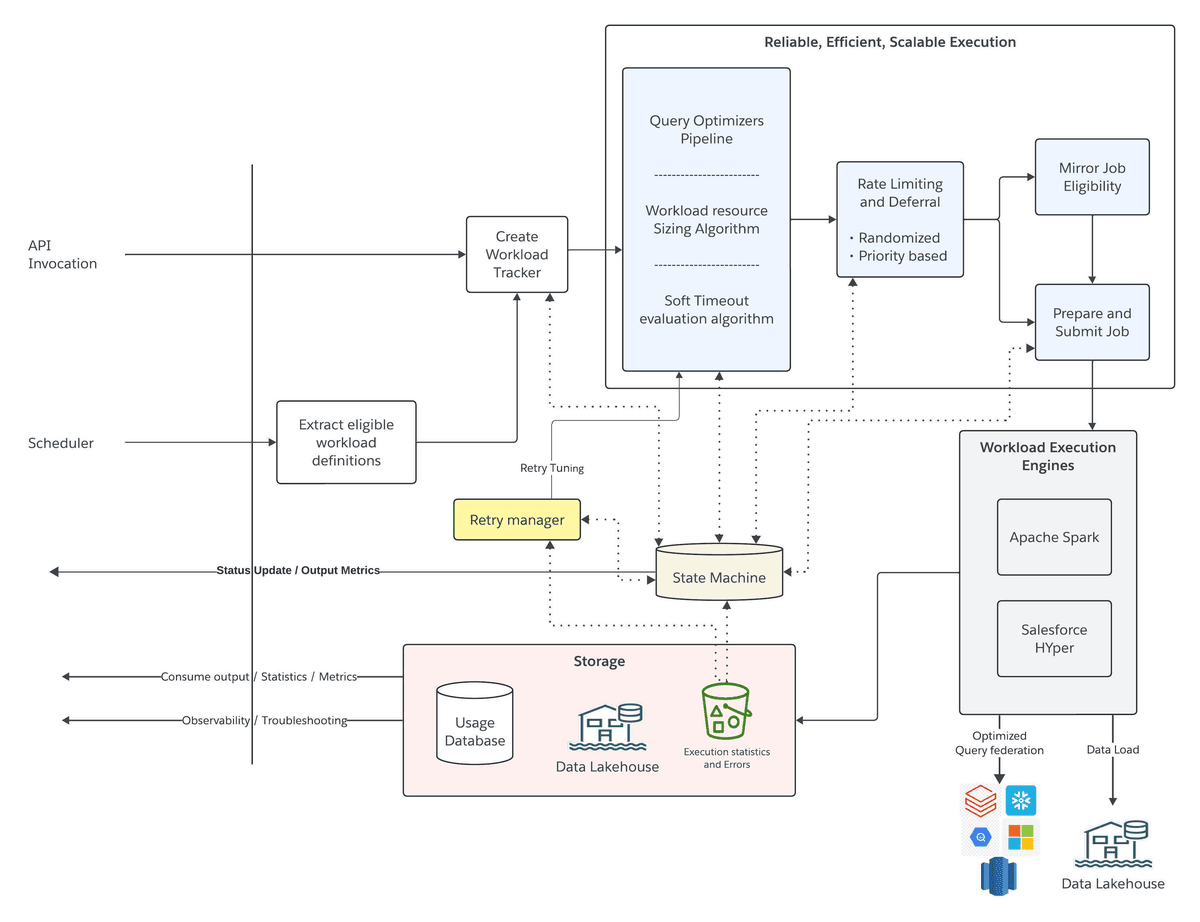
O Data 360 da Salesforce não é só um CDP: é uma infraestrutura de dados em tempo real projetada para escalar com o caos, e o caos aqui é estruturado. Ele lida com 1 quatrilhão de registros/mês não apesar da variabilidade, mas *porque* foi construído para absorvê-la: schemas customizados, grafos de relacionamento dinâmicos, múltiplos back-ends (Snowflake, BigQuery, Databricks, Fabric) via Zero Copy File Federation, e até 6.000 tabelas por ambiente. O que torna isso viável é a interpretação em tempo de execução dos metadados do cliente, não um schema fixo, mas um motor que lê, valida e recompõe relações na hora do job Spark. Mas essa flexibilidade tem um preço: os metadados viraram o novo bottleneck. Um payload de 500 MB não é só um problema de UI lenta; é um sintoma de que o sistema está tentando carregar, serializar e explorar bilhões de planos de consulta candidatos antes mesmo de executar uma única linha de código.
Isso coloca o Data 360 no mesmo time de sistemas como mondayDB 3 (trilhões de tabelas) e o monitoramento da Databricks (10 trilhões de amostras/dia): todos enfrentam o colapso da camada de metadados quando a escala ultrapassa o limite de ‘gestão humana’. A resposta da Salesforce, planejamento de consulta em fases, é pragmática, mas revela um tradeoff crítico: otimização local em vez de global. Não é um bug, é uma escolha arquitetural explícita para manter SLA em ambientes onde cada cliente define seu próprio universo de dados.
O que mudou
A cobertura anterior de 17 de junho já destacava a arquitetura adaptativa do Data 360, mas tratava metadados como um desafio operacional secundário. Agora, em 18 de junho, a Salesforce confirma que a gestão de metadados deixou de ser um ponto de atenção e se tornou a *principal restrição arquitetural*, com impacto direto em query planning, workload execution e usabilidade. Isso reflete uma evolução real: o sistema passou da fase de ‘escalar os dados’ para a fase de ‘escalar a compreensão dos dados’. Também houve mudança conceitual: o antigo ‘Data Cloud’ foi renomeado oficialmente para ‘Data 360’ na Dreamforce 2025, e sua integração com Agentforce (agentes de IA) deixou de ser promessa para ser exigência funcional, o que eleva ainda mais o custo da lentidão no plano de consulta.
Por que isso importa
Para engenheiros de dados, isso não é só sobre performance: é sobre governança em escala. Se o plano de consulta leva minutos para ser gerado, você não consegue auditar, testar ou versionar alterações de modelo com segurança. Se os metadados são carregados em blocos de 500 MB, ferramentas de CI/CD como CLI ou Change Sets ficam limitadas, e equipes recorrem a scripts personalizados ou soluções de terceiros (Elements.cloud, CapStorm, Metadata GPT). Para quem constrói pipelines com Zero Copy, o gargalo de metadados afeta diretamente o custo: um plano ruim gera mais leituras externas, mais créditos consumidos, e menos eficiência no uso de recursos. Em resumo: a próxima fronteira do data engineering não é processar mais dados, mas fazer com que o sistema entenda melhor o que ele já sabe.
Linha do tempo
Lançamento da arquitetura Iceberg File Federation para Zero Copy, escalando de 1 trilhão para 120 trilhões de linhas
Cobertura CEVIU detalha a arquitetura adaptativa do Data 360, mas ainda não identifica metadados como gargalo principal
Confirmação de que gestão de metadados é agora a principal restrição arquitetural, com payloads >500 MB e bilhões de planos de consulta candidatos
Perguntas frequentes
Por que metadados viraram gargalo se o Data 360 foi feito para lidar com esquemas variáveis?
Porque a flexibilidade exige que o sistema processe *toda* a estrutura de relacionamentos em tempo real, não apenas os dados. Com 3.000, 6.000 tabelas e milhares de relações, o número de combinações possíveis para um único segmento explode. O planejamento de consulta vira um problema de busca combinatória, não de execução.
O que muda na prática para quem usa Data 360 após essa descoberta?
Time-to-market de novos segmentos pode aumentar em ambientes grandes. Equipes precisam priorizar modelagem limpa (evitar relações cíclicas, reduzir cardinalidade excessiva) e usar ferramentas de análise de impacto (como Elements.cloud) antes de implantar mudanças. Também vale revisar o uso de Data Kits, empacotar metadados em blocos menores melhora a deployabilidade.
Como o Zero Copy se relaciona com esse gargalo de metadados?
Zero Copy reduz custo de movimentação de dados, mas aumenta a complexidade do plano de consulta: agora o sistema precisa entender não só o schema local, mas também os esquemas remotos (Snowflake, BigQuery etc.) e como unificá-los. Cada fonte externa adiciona novas camadas de metadados a serem avaliadas, e isso multiplica o volume de planos candidatos.
Essa limitação afeta só clientes grandes, com milhares de tabelas?
Não. O gargalo aparece em escala, mas o efeito cascata atinge todos: o planejamento lento retarda alertas, dificulta rollback automático e prejudica a capacidade de detectar falhas proativamente, como mostrado no caso da Databricks com 10 trilhões de amostras/dia, onde observabilidade também virou prioridade crítica.
Fontes
- engineering.salesforce.comfonte original
- Categoria
- CEVIU Dados
- Publicado
- 18 de junho de 2026
- Editoria
- CEVIU Dados