Como o Data 360 da Salesforce processa um quatrilhão de registros mensais com arquitetura adaptativa em Spark
Aprofundamento CEVIU
Aprofundamento
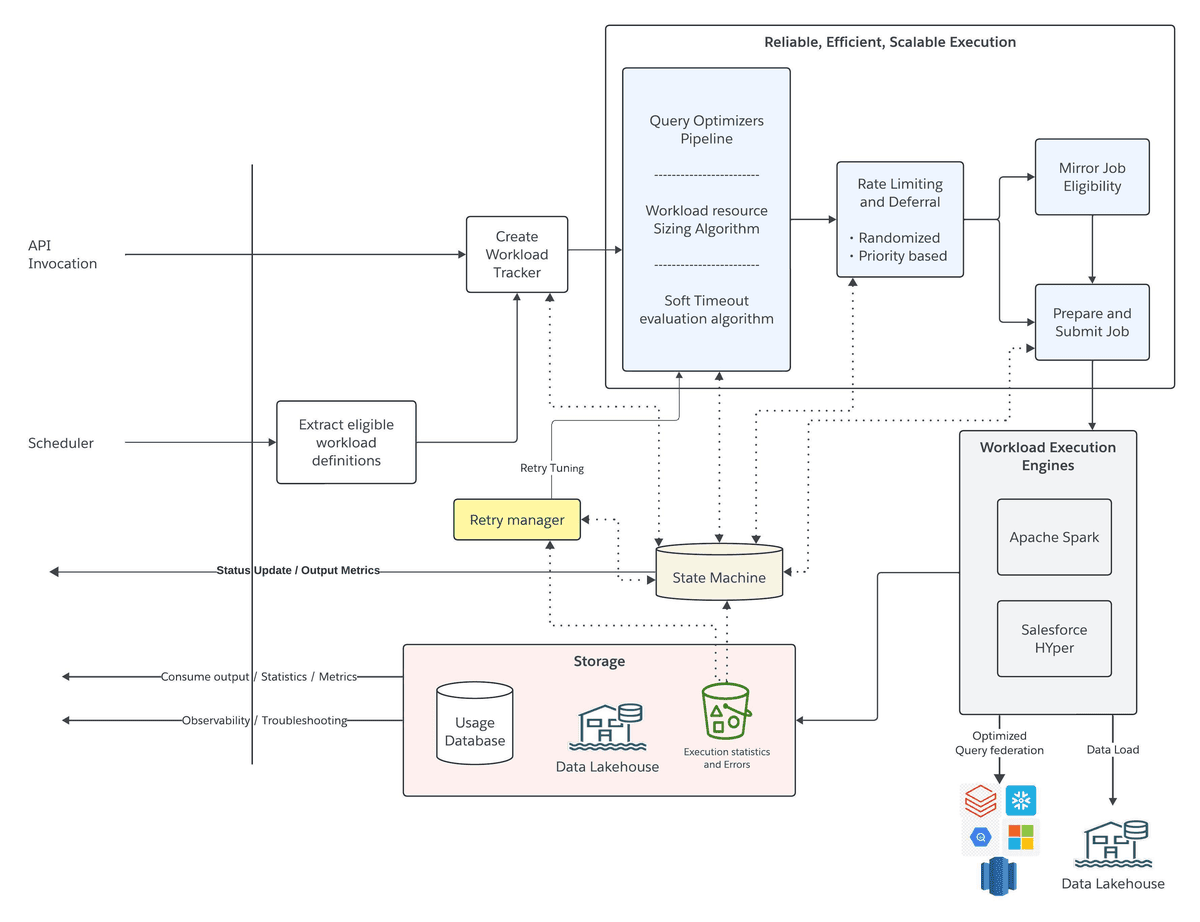
O Data 360 da Salesforce não é só um CDP: é a camada de dados operacional que sustenta toda a estratégia de IA autônoma da empresa, incluindo os agentes Agentforce, que já geraram mais de US$ 100 milhões em pipeline. A arquitetura de segmentação descrita na notícia atual é o coração desse sistema: ela transforma milhares de tabelas heterogêneas (4 milhões de tabelas Iceberg, 50 PB de dados) em públicos acionáveis em tempo real, sem impor esquemas rígidos. Isso só é viável porque o motor roda sobre uma stack lakehouse com Iceberg como abstração central, Parquet em S3 e execução híbrida via Spark, Hyper e Trino, não um data warehouse tradicional.
A confiabilidade de 99,95% não vem de overprovisioning, mas de orquestração inteligente: estimativa dinâmica de carga evita falhas por skew ou explosão cartesiana; retentativas orientadas por SLA garantem que um segmento para campanha de email não fique preso em retry cego; e a telemetria em produção alimenta sistemas automatizados de diagnóstico, essencial quando 100 mil jobs Spark rodam diariamente e até um erro de 0,05% gera milhares de alertas. Essa engenharia é decisiva para governança: sem ela, a promessa de 'dados unificados para visão 360°' vira apenas mais um silo com custos de manutenção crescentes.
O que mudou
Em abril de 2026, o Data 360 passou de Query Federation para Iceberg File Federation, o que permitiu escalar o Zero Copy de 1 trilhão para 120 trilhões de linhas mensais. Agora, a nova arquitetura de segmentação processa um quatrilhão de registros por mês com a mesma base: grafos de relacionamento executados em runtime, não em compile-time. Antes, a limitação estava no planejamento de consultas, com ambientes de 6.000 tabelas, o query planner avaliava bilhões de caminhos. Hoje, o phased planning reduz isso a estágios gerenciáveis, mantendo SLAs mesmo com cargas variáveis de 10 mil a 100 bilhões de registros por job. O que era rumor em 2025 (‘execução adaptativa em Spark’) agora é métrica operacional: alocação dinâmica de recursos, rate limiting entre clientes e telemetria granular por workload são padrão.
Por que isso importa
Para empresas migrando para nuvem híbrida ou multi-cloud, essa arquitetura define o custo real de adoção de IA: não é o preço da licença, mas o custo oculto de governança, qualidade de dados e latência entre fonte e ação. Um cliente que usa Snowflake + Salesforce + Databricks não precisa escolher onde centralizar dados, o Zero Copy File Federation faz a ponte sem cópia, com custo 28,5x menor que ETL tradicional. Mas isso só funciona se a camada de segmentação for capaz de interpretar schemas arbitrários em runtime, sem depender de modelagem prévia. Para TI corporativa, isso muda o jogo de compliance: dados sensíveis permanecem na origem, mas ainda alimentam fluxos de personalização em tempo real, atendendo a LGPD e CCPA sem sacrificar agilidade.
Linha do tempo
Airbnb lança sistema de métricas com shuffle sharding para 1,3 bilhão de séries temporais
Benchmark mostra Postgres sustentando 43 mil workflows duráveis por segundo
Databricks reestrutura monitoramento para 10 trilhões de amostras diárias com Pantheo
Salesforce evolui Zero Copy para Iceberg File Federation, escalando para 120 trilhões de linhas
Data 360 processa um quatrilhão de registros mensais com arquitetura adaptativa em Spark
Perguntas frequentes
O que significa 'schemas definidos pelo cliente em runtime' na prática?
Significa que o motor de segmentação não exige que o cliente normalize seus dados antes de usar o Data 360. Ele lê diretamente tabelas com nomes, tipos e relacionamentos customizados, como 'conta_vip', 'transacao_bruta_2026' ou hierarquias aninhadas, e constrói o grafo de execução dinamicamente, sem precisar de migrações ou conversões manuais.
Como o Data 360 evita que um cliente com má modelagem afete outros?
Através de rate limiting granular por tenant, alocação adaptativa de recursos por job (não por cluster) e isolamento de metadados. Se um cliente tem 5.000 tabelas com relacionamentos mal definidos, o phased query planning contém o impacto no tempo de planejamento, sem travar a interface ou sobrecarregar o query planner global.
Qual é a diferença prática entre Segmentos Padrão, em Cascata e em Tempo Real?
Segmentos Padrão persistem resultados e suportam SQL complexo, ideais para relatórios mensais. Em Cascata criam grupos mutuamente exclusivos (ex: 'premium > gold > silver') com prioridade explícita. Em Tempo Real usam streaming para avaliar eventos em milissegundos, como 'cliente que abandonou carrinho há 90 segundos', acionando imediatamente um push personalizado.
Por que a mudança para Iceberg File Federation foi tão crítica?
Query Federation exigia tradução SQL em tempo real para cada sistema externo, causando overhead e inconsistências. Iceberg File Federation acessa diretamente os arquivos Parquet no data lake, aproveitando metadata nativa do Iceberg, o que reduziu o custo de federação em 28,5x e permitiu ingestão de 15 trilhões de registros trimestrais via Zero Copy, um aumento de 341% ano a ano.
Fontes
- engineering.salesforce.comfonte original
- Categoria
- CEVIU TI
- Publicado
- 17 de junho de 2026
- Editoria
- CEVIU TI