Balanceamento no cliente a um milhão de requisições por segundo
Aprofundamento CEVIU
Aprofundamento
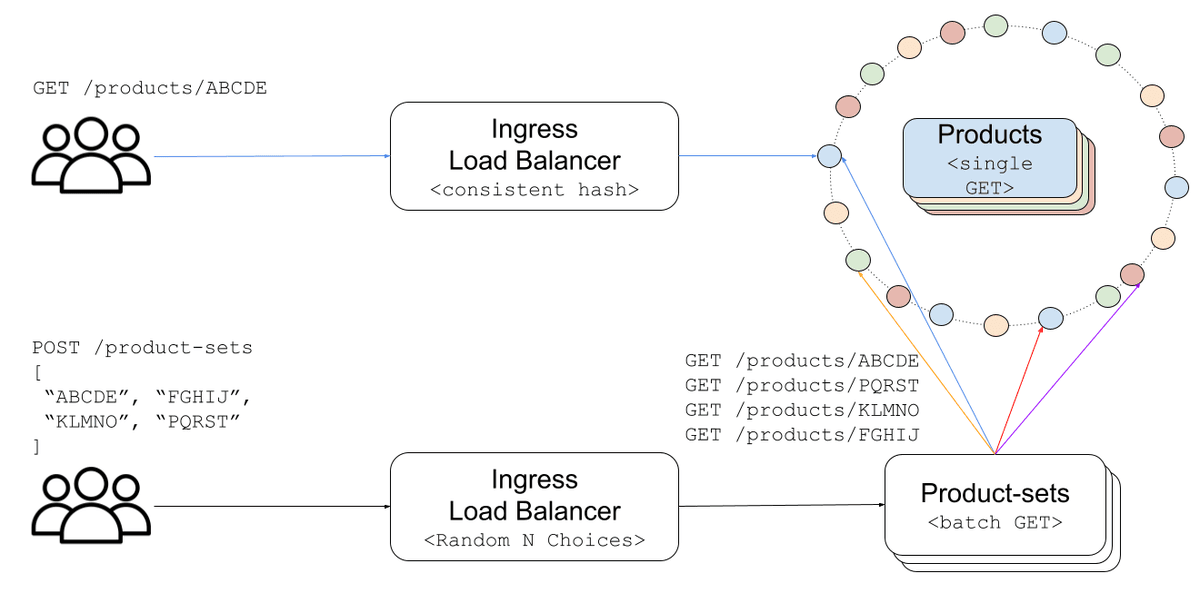
A Zalando enfrentava um dilema clássico em sistemas de alta escala: como isolar a latência crítica de uma API central quando ela depende de infraestrutura compartilhada. A Product Read API (PRAPI), que sustenta todas as interações de produto na plataforma, estava sujeita a picos de latência difíceis de diagnosticar porque o tráfego interno de fan-out passava pelo ingress Skipper, também usado por outros serviços. O time descobriu que, mesmo com adição mínima de latência por chamada (centenas de microssegundos), o efeito combinado em requisições que geravam até 100 chamadas paralelas amplificava o tail latency, já que a resposta final dependia do pior caminho. A solução foi mover o balanceamento para o cliente (CSLB), mas não de forma genérica: replicaram exatamente o algoritmo de hash consistente do Skipper (xxHash64 com 100 virtual nodes por endpoint) para garantir paridade total no roteamento e evitar fragmentação de cache. Isso permitiu migrar progressivamente com chave de corte e fallback transparente, mantendo métricas comparáveis em tempo real.
O sistema usa informers do Kubernetes com watch em EndpointSlices para descoberta eficiente de pods, evitando sobrecarga no control plane com polling distribuído. Em caso de falha na API, o último estado válido é mantido, garantindo continuidade. Todo o componente foi escrito como módulo JVM leve, sem framework, aproveitando bibliotecas zero-allocation e integrando Micrometer para métricas. A arquitetura imutável com snapshots atômicos permite atualizações concorrentes sem bloqueios, essencial para desempenho em alto volume.
Por que isso importa
Este caso mostra como equipes de engenharia de elite atacam problemas sistêmicos com soluções precisas, não generalistas. Em vez de reinventar o balanceamento, a Zalando copiou fielmente o comportamento existente para reduzir risco. O verdadeiro ganho veio depois: ao internalizar o controle de roteamento, puderam implementar otimizações impossíveis antes. O N-ring fade-in, por exemplo, garante que novos pods recebam exatamente o tráfego que servirão no estado estável, eliminando aquecimento ineficiente. Já a mudança de métrica de balanceamento, de in-flight requests para occupancy (tempo de trabalho por segundo), revelou desequilíbrios ocultos e permitiu uso mais eficiente dos recursos. O resultado foi queda direta de latência, maior estabilidade e surpreendente redução de custo: o cluster do Skipper encolheu de mais de 50 para 8 pods. Isso transformou um projeto técnico em ganho operacional e financeiro.
Perguntas frequentes
Por que o balanceamento no cliente foi necessário se o Skipper já era rápido?
Mesmo com baixa latência por chamada, o fan-out interno multiplicava o impacto: uma requisição batch esperava pelas 100 chamadas paralelas, ficando presa ao pior caminho. Além disso, o uso de infraestrutura compartilhada tornava difícil isolar causas de lentidão. Ao mover o balanceamento para o cliente, a Zalando removeu essa dependência e ganhou visibilidade e controle sobre o roteamento.
Como garantiram que o novo balanceador não quebrasse o cache?
Implementaram exatamente o mesmo algoritmo de hash consistente do Skipper: xxHash64 com 100 posições virtuais por endpoint em um anel de 64 bits. Testes unitários validam em cada build que o roteamento é idêntico ao do Skipper. Na produção, durante a migração gradual, as taxas de acerto de cache permaneceram iguais nos dois caminhos.
O que é N-ring fade-in e por que é melhor que o fade-in tradicional?
N-ring fade-in cria um anel temporário para cada evento de escalonamento, com curva configurável (^2.5). Novos pods recebem tráfego proporcional ao seu estágio de aquecimento, mas com base no tráfego real que terão no estado estável. Isso evita desperdício de cache e choque no banco de dados. Eventos subsequentes não interrompem o fade anterior, pois cada um tem janela independente.
Qual foi o impacto real na operação após a migração?
Além da melhoria esperada em latência e estabilidade, houve redução significativa de custo: o cluster do Skipper para essas rotas passou de mais de 50 pods para apenas 8. Também ganharam flexibilidade para otimizar continuamente, como com o uso de occupancy em vez de in-flight para balanceamento, algo impossível antes de controlar o roteamento.
Fontes
- engineering.zalando.comfonte original
- Categoria
- CEVIU Dados
- Publicado
- 25 de junho de 2026
- Editoria
- CEVIU Dados