Como a engenharia da Zalando escalou o balanceamento de carga no lado do cliente para 1 milhão de RPS
Aprofundamento CEVIU
Aprofundamento
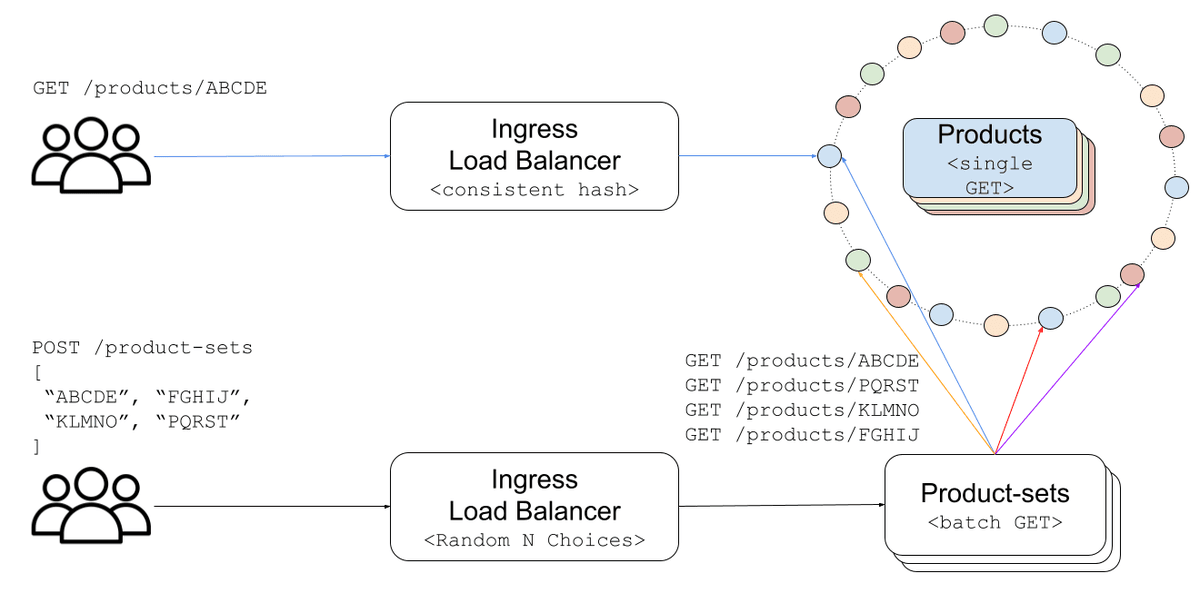
Skipper é um roteador HTTP e controlador de ingresso Kubernetes desenvolvido pela Zalando em Go, projetado para composição de serviços, não como balanceador genérico, mas como uma ferramenta de roteamento inteligente com suporte nativo a consistent-hash, proteção contra sobrecarga e fade-in controlado Skipper no GitHub. Ele funciona bem na borda, mas sua natureza compartilhada e global tornou-se um gargalo para tráfego interno de alta fan-out, como o da Product Read API (PRAPI), onde cada requisição em lote de 100 produtos gerava 100 chamadas individuais passando por Skipper, multiplicando latência, obscurecendo causas de falhas e impedindo visibilidade real de comportamento do serviço.
O novo client-side load balancer da Zalando não é um substituto genérico, mas uma implementação JVM *específica* para o caso crítico de PRAPI. Ele replica exatamente o algoritmo de hash ring do Skipper (xxHash64 com 100 nós virtuais), garante paridade absoluta de roteamento durante migração e opera dentro do processo, sem dependências externas além do JDK, Micrometer e um cliente Kubernetes watch-based. Isso elimina o salto de rede, remove o ponto único de falha compartilhado e dá controle total sobre sinais de carga, como a métrica de *occupancy* (trabalho em segundos por segundo), que revelou desequilíbrios reais escondidos por contadores de requisições em voo.
O que mudou
A cobertura CEVIU de 25/06/2026 já detalhava a existência do novo balanceador in-process e sua capacidade de 1 milhão de RPS. O que mudou agora é a divulgação técnica completa do *como*: a implementação concreta da N-ring fade-in (não apenas 'fade-in', mas múltiplos anéis imutáveis com curvas independentes), a troca definitiva do sinal de carga de *in-flight requests* para *occupancy*, e a confirmação de que a migração foi feita com fallback transparente e toggles granulares, não como experimento, mas como operação estável em produção com impacto mensurável em custo (redução de 50 para 8 pods no Skipper) e resiliência.
Por que isso importa
Para devs brasileiros que lidam com microsserviços em Kubernetes, essa arquitetura mostra que client-side load balancing não é só sobre performance, é sobre *propriedade*. Ao tirar o roteamento do caminho crítico compartilhado, a equipe ganhou diagnóstico preciso, reduziu dependência de infraestrutura centralizada e pôde otimizar sinais de carga com base no tempo real de processamento, não em contagens superficiais. Isso eleva a DX porque os engenheiros passam a medir o que realmente importa: quanto tempo um pod está ocupado servindo, não quantos requests estão pendentes. E isso muda decisões de escalonamento, cache e até design de APIs.
Linha do tempo
CEVIU publica primeira cobertura sobre o client-side load balancer da Zalando para PRAPI, destacando a escala de 1 milhão de RPS
Zalando publica detalhes técnicos completos da implementação, incluindo N-ring fade-in, occupancy como sinal de carga e rollout com toggles
Perguntas frequentes
Por que a Zalando não usou um client-side load balancer genérico, como o do gRPC ou do Envoy?
Eles precisavam de paridade exata com o Skipper para evitar divisão de cache e duplicação de leituras no DynamoDB. Um LB genérico teria usado outro algoritmo de hash, quebrando a consistência. A solução foi construir um módulo JVM com o mesmo xxHash64 e mesma lógica de anel virtual, não um wrapper, mas uma réplica funcional.
O que é 'occupancy' e por que é melhor que 'in-flight requests' para balanceamento?
Occupancy mede segundos de trabalho por segundo, por exemplo, um pod que gasta 0,8s servindo requisições em cada segundo tem occupancy 0,8. Já 'in-flight' conta apenas requisições abertas no instante da leitura. Occupancy revela carga real entre picos e distingue pods rápidos com cache quente de lentos com cache frio, algo que 'in-flight' mascara completamente.
Como o sistema lida com falhas no Kubernetes API durante o watch dos EndpointSlices?
O balanceador mantém a última lista válida de endpoints em memória. Se o watch cair, ele continua roteando com o anel atual. Erros de conexão são tratados no nível HTTP pelo cliente, com retry e fallback automático para Skipper, sem interrupção de tráfego ou anel vazio.
Essa abordagem se aplica a qualquer microsserviço ou só à PRAPI?
É mais adequada para serviços com alto fan-out interno (como batches de 100+ chamadas), baixa latência exigida (milissegundos) e dependência crítica de cache local. Para APIs simples ou com pouca fan-out, o overhead de manter o anel e o watch pode não valer a pena, Skipper ainda é a escolha certa na borda.
Links relacionados
Fontes
- engineering.zalando.comfonte original
- Categoria
- CEVIU Web Dev
- Publicado
- 03 de julho de 2026
- Editoria
- CEVIU Web Dev