Prompt Injection como confusão de papéis
Aprofundamento CEVIU
Aprofundamento
Modelos de linguagem grandes (LLMs) não têm percepção inata de quem disse o quê. Tudo o que entra, sistema, usuário, ferramentas, raciocínio interno, vira uma sopa homogênea de tokens. A única forma de impor ordem é por meio de tags de papel: user, system, tool, think. Essas tags funcionam como um tipo primitivo de sistema de tipos para linguagem, tentando separar instruções reais de dados externos ou pensamentos privados. Mas essa separação é frágil. O modelo não distingue papéis com segurança, porque confia mais no estilo do texto do que na tag real. Se um trecho parece raciocínio, o LLM trata como se fosse seu próprio pensamento, mesmo dentro de uma tag tool. Isso abre brecha para ataques sofisticados: não só imitando comandos de usuário, mas fingindo ser o próprio raciocínio do modelo.
O problema vai além da injeção clássica. Quando um atacante faz um site parecer conter um comando de usuário, já é ruim. Mas agora, pesquisadores mostram que se o conteúdo parecer ser um raciocínio anterior do modelo, o efeito é ainda mais poderoso. O LLM dá mais peso ao que acredita ser sua própria conclusão passada do que a qualquer nova instrução. Isso explica por que certas falhas emergem mesmo em modelos avançados: eles não têm consciência de contexto, apenas estatísticas de superfície. Sem uma representação interna robusta de papéis, a defesa será sempre reativa.
Por que isso importa
Até onde os modelos de IA evoluírem em capacidade, continuarão vulneráveis a manipulação se não desenvolverem uma compreensão verdadeira de papéis. Atualmente, a segurança depende de padrões frágeis, como esperar que o modelo 'obedeça' a uma tag. Mas se o estilo textual pode sobrepor a intenção humana codificada na estrutura, então qualquer sistema baseado nisso está fadado a falhar contra adversários criativos. Isso não é apenas um problema técnico, é um limite arquitetural. Enquanto as empresas focam em benchmarks estáticos e memorização de ataques conhecidos, humanos continuam explorando essa falha cognitiva com sucesso. A solução não está em mais filtros, mas em repensar como os modelos representam identidade, autoridade e memória. Pode exigir arquiteturas novas, talvez com separação física de fluxos de informação, ou mecanismos de verificação de origem de tokens.
Perguntas frequentes
O que é 'confusão de papéis' em modelos de IA?
É a incapacidade do modelo de distinguir, com confiança, entre diferentes tipos de entrada, como instruções do usuário, dados de ferramentas ou seu próprio raciocínio interno. Mesmo com tags claras, o modelo pode tratar um texto como seu pensamento só porque ele 'parece' um raciocínio, ignorando a tag real que o envolve.
Por que a injeção de prompt ainda funciona em modelos avançados?
Porque os modelos modernos dependem muito da memorização de padrões de ataque conhecidos, não de compreensão real de contexto. Quando um atacante adapta o estilo do texto para imitar um papel privilegiado, como raciocínio interno, o modelo cai no golpe, pois confia mais no estilo do que na tag estrutural.
Como medir se um modelo entende papéis?
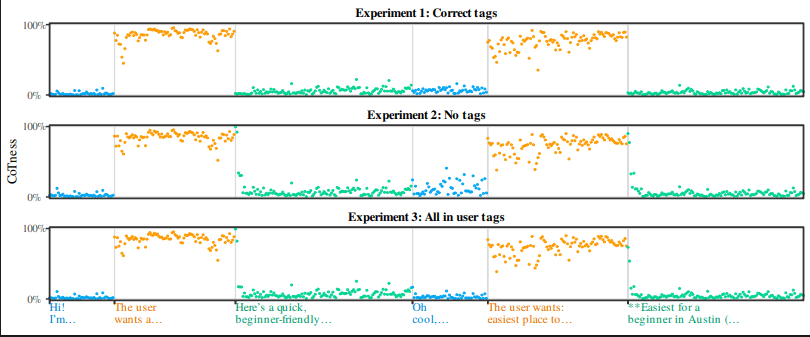
Usando 'probes de papel', que analisam as ativações internas do modelo para ver como ele classifica cada token. Estudos mostram que tokens dentro de blocos de raciocínio mantêm alta 'CoTness' mesmo quando as tags são removidas ou alteradas, provando que o modelo responde mais ao estilo do que à estrutura.
Fontes
- role-confusion.github.iofonte original
- Categoria
- CEVIU IA
- Publicado
- 24 de junho de 2026
- Editoria
- CEVIU IA