NVIDIA NeMo AutoModel acelera fine-tuning de Transformers
Aprofundamento CEVIU
Aprofundamento
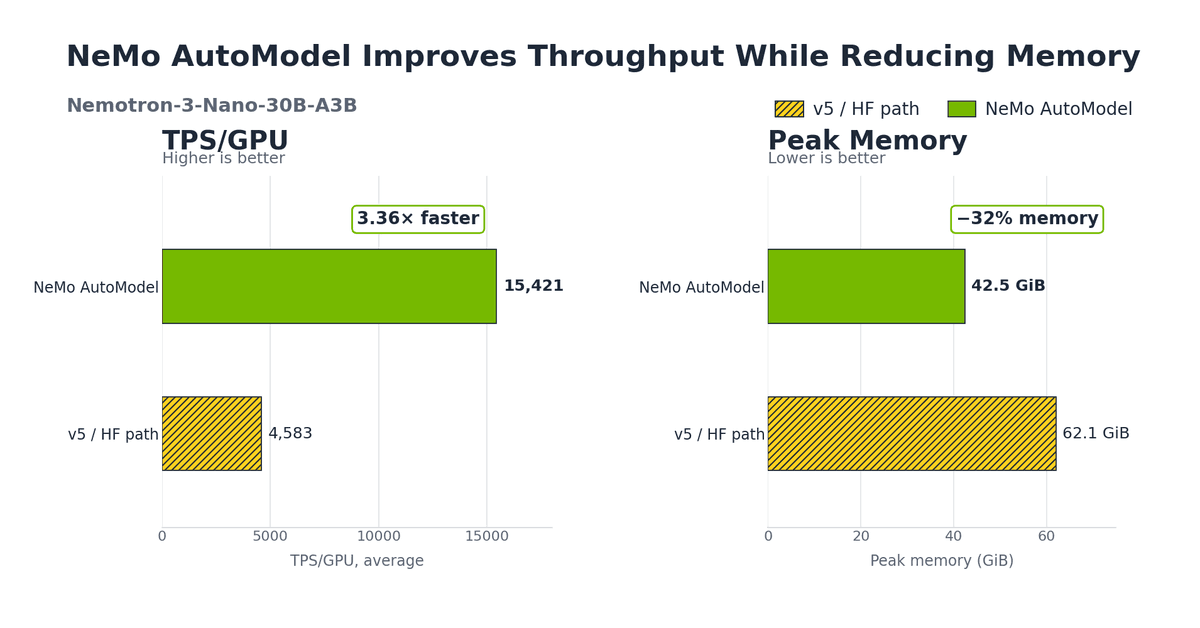
O lançamento do NVIDIA NeMo AutoModel no Hugging Face representa um avanço técnico concreto na escalabilidade de modelos Mixture-of-Experts (MoE), que hoje dominam o cenário de modelos de linguagem de ponta. A solução não é apenas uma otimização isolada, mas sim uma camada crítica que atua sobre a arquitetura base do Transformers v5, aproveitando suas melhorias em suporte a MoE, como carregamento dinâmico de pesos e planos de paralelismo tensorial, para entregar ganhos reais em throughput e uso de memória. O diferencial está na combinação de três pilares: Expert Parallelism (EP) para sharding dos experts entre GPUs, DeepEP fused all-to-all dispatch que sobrepõe comunicação com cálculo, e kernels do TransformerEngine para operações críticas como atenção e normalização.
Esses ganhos são medidos em cenários reais: até 3,7x mais throughput em fine-tuning e redução de 32% no pico de memória GPU em modelos como Qwen3-30B e Nemotron 3 Nano. Em escala maior, o framework torna possível o fine-tuning completo de modelos de 550B de parâmetros, algo inviável com Transformers v5 por estouro de memória. Isso abre caminho para treinar modelos personalizados com custo controlado, especialmente em ambientes com hardware limitado, sem precisar mudar a API ou reescrever código existente.
Por que isso importa
A aceleração do fine-tuning de MoE não é só uma melhoria de performance: é um passo estratégico para democratizar o acesso a modelos de alto desempenho. Com a crescente complexidade dos modelos, a eficiência em treinamento determina quem pode competir no espaço de IA. O NeMo AutoModel elimina barreiras técnicas, como deadlocks em FSDP causados por loops dependentes de dados e falta de balanceamento de carga, ao usar uma abordagem com EP ortogonal ao data parallelism, permitindo escalabilidade real em múltiplos nós. Além disso, manter o formato padrão de checkpoints do Hugging Face garante compatibilidade com ferramentas de inferência como vLLM e SGLang, fechando o ciclo de desenvolvimento desde treino até deploy.
Para equipes que já usam Transformers, a migração é mínima: basta trocar um import. Isso transforma o NeMo AutoModel em uma solução prática para quem busca resultados imediatos sem sacrificar flexibilidade. No contexto da corrida global por eficiência em IA, essa entrega direta de ganhos técnicos com baixo custo de adoção é um sinal claro de que o foco agora está em infraestrutura otimizada, não apenas em tamanho de modelo.
Linha do tempo
NVIDIA lança NeMo AutoModel no Hugging Face para otimizar fine-tuning de modelos MoE com até 3,7x mais throughput e 32% menos uso de memória GPU.
Perguntas frequentes
O NeMo AutoModel substitui o Hugging Face Transformers v5?
Não. Ele se integra ao v5 como uma extensão. Funciona sobre a mesma API, mantendo compatibilidade com modelos existentes. A mudança é apenas no import: de 'transformers' para 'nemo_auto_model'.
Por que o Transformers v5 falha em treinar modelos de 550B?
O v5 não implementa Expert Parallelism como dimensão separada. Quando os experts são armazenados como módulos individuais, o FSDP entra em conflito com distribuição irregular de tokens, levando a deadlocks ou estouro de memória em grandes modelos.
É necessário mudar o código para usar o NeMo AutoModel?
Não. O modelo é compatível com AutoModelForCausalLM. Basta alterar a linha de importação. O restante do pipeline de fine-tuning funciona como antes, com ganhos automáticos em velocidade e memória.
Como o DeepEP melhora o desempenho?
Ele funde operações de roteamento de tokens com cálculos dos experts, sobrepõe comunicação entre GPUs com processamento e evita chamadas separadas de AllGather/ReduceScatter, reduzindo latência e aumentando a utilização da GPU.
Fontes
- huggingface.cofonte original
- Categoria
- CEVIU IA
- Publicado
- 25 de junho de 2026
- Editoria
- CEVIU IA