4.0-H-350M: liquid AI lança o Liquid Foundation Model 2.5 com 230 milhões de parâmetros
Aprofundamento CEVIU
Aprofundamento
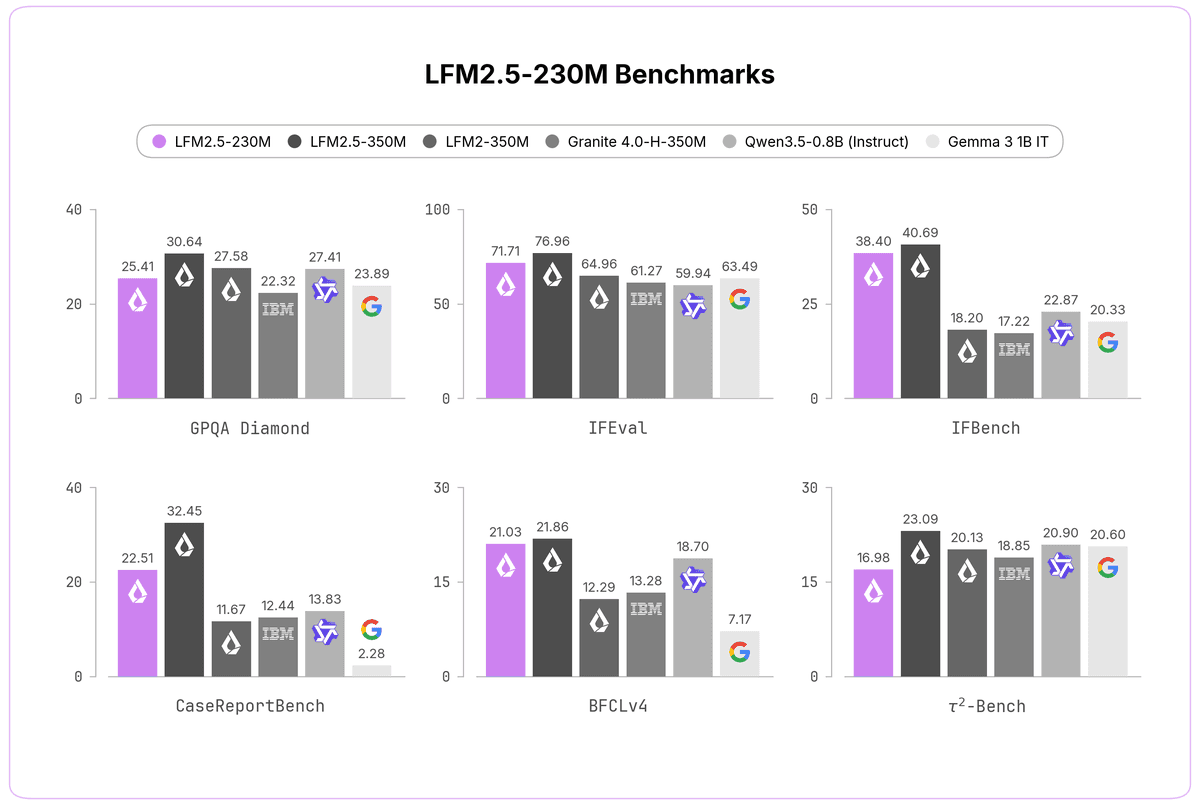
A Liquid AI entregou o 4.0-H-350M como base arquitetural para o novo Liquid Foundation Model 2.5, versão compacta com 230 milhões de parâmetros. O modelo abandona o transformer e adota redes neurais líquidas com formulações de tempo contínuo e state-space. A equipe treinou a rede em 19 trilhões de tokens e incluiu fase de extensão para 32K de contexto. O pipeline de pós-treinamento usa distilação supervisionada do LFM2.5-350M, otimização direta por preferência e reforço multi-domínio. O resultado roda em hardware de borda com latência mínima e suporta ferramentas nativas como llama.cpp, MLX e vLLM. Consulte o artigo original para acesso direto aos pesos.
O foco atende fluxos agênticos leves e extração de dados em escala. A arquitetura entrega paridade com modelos de referência três vezes maiores em testes de raciocínio de borda e uso de ferramentas. A empresa já colocou a rede no robô humanóide Unitree G1 com Jetson Orin para atuar como camada de seleção de habilidades. O modelo não substitui redes pesadas. A Liquid AI avisa para evitar o 230M em matemática avançada, geração de código e escrita criativa. O código é open-weight e roda direto no Hugging Face.
Por que isso importa
A corrida por IA de borda exige modelos que caibam em memória restrita sem sacrificar throughput. O 4.0-H-350M e sua variante de 230M mostram que state-space já compete com transformer em produção real. Empresas podem rodar pipelines de extração e orquestração de agentes em Raspberry Pi ou smartphones, cortando custos de GPU e latência de rede. A abordagem open-weight e a compatibilidade com inferência nativa em Apple, AMD e Qualcomm aceleram a adoção em IoT e robótica embarcada. O futuro da IA descentralizada depende desse equilíbrio entre tamanho, velocidade e capacidade de fine-tuning rápido.
Perguntas frequentes
Qual a diferença entre LFM2.5-230M e um transformer tradicional?
O LFM2.5 usa redes neurais líquidas com formulação de tempo contínuo e state-space em vez da atenção global dos transformers. Essa escolha reduz o consumo de memória e aumenta a velocidade de inferência em dispositivos de borda. O modelo mantém a capacidade de lidar com contexto de 32K tokens e processamento sequencial eficiente.
O modelo serve para gerar código ou resolver problemas matemáticos complexos?
Não. A Liquid AI recomenda evitar o modelo de 230M para raciocínio pesado, geração de código ou escrita criativa. A arquitetura foi otimizada para extração de dados, uso de ferramentas e fluxos agênticos leves. Modelos maiores ou especializados ainda são necessários para tarefas cognitivas complexas.
Como rodar a IA localmente ou em robótica embarcada?
A empresa disponibiliza checkpoints GGUF para llama.cpp, otimizações para Apple Silicon via MLX e suporte a vLLM e SGLang para servidores. O modelo já foi testado no Unitree G1 com NVIDIA Jetson Orin para decompor comandos naturais em chamadas de ferramenta. O ajuste fino local é direto e roda em CPU com latência previsível.
Fontes
- liquid.aifonte original
- Categoria
- CEVIU IA
- Publicado
- 26 de junho de 2026
- Editoria
- CEVIU IA