GLM-5.2 eleva a régua entre os modelos abertos
Aprofundamento CEVIU
Aprofundamento
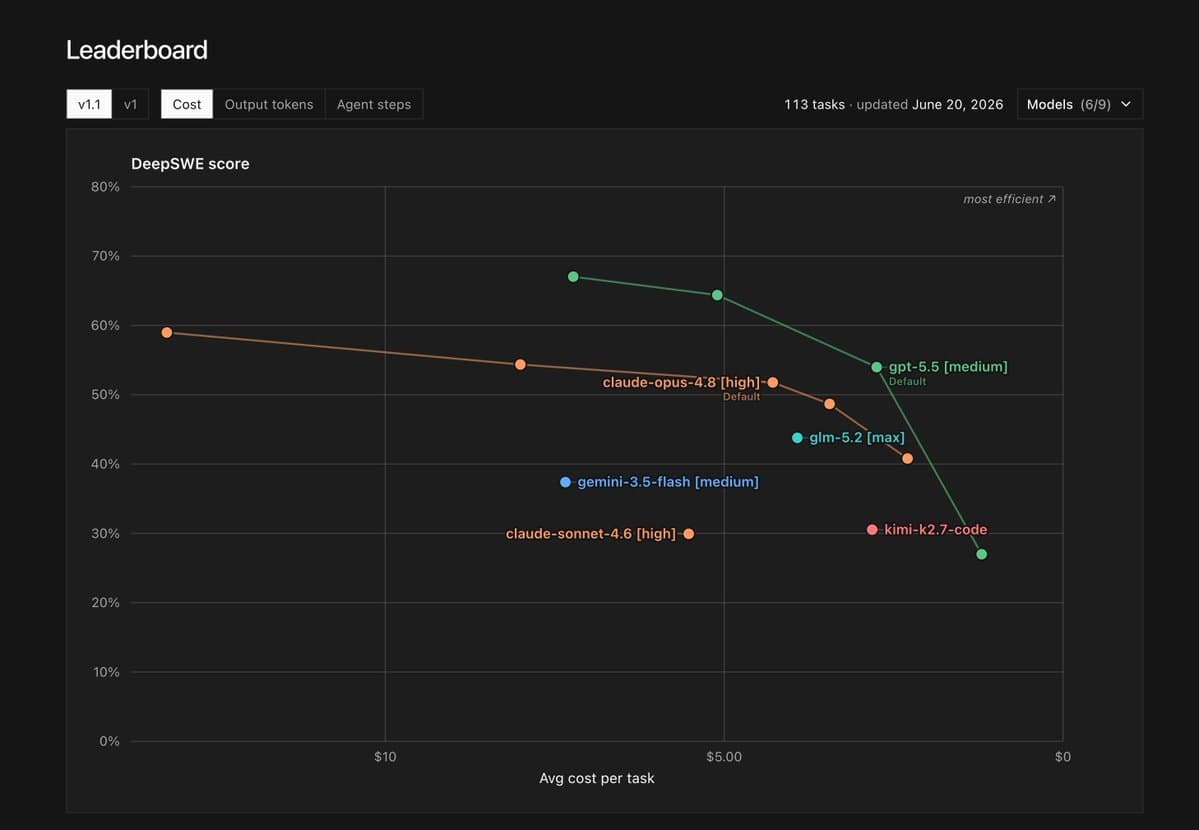
GLM-5.2 não é só mais um modelo aberto: ele quebra o padrão de que modelos chineses ficam sempre atrás da fronteira ocidental. Pela primeira vez, um modelo aberto da China supera GPT-5.4 e todas as versões de Gemini em benchmarks de desempenho puro, sem recorrer a arquiteturas fechadas ou treinamento exclusivo. O resultado é um modelo que, apesar de distilado de Claude Opus, entrega desempenho comparável a modelos de ponta em tarefas complexas de raciocínio e codificação, como resolver o Project Euler 1003 ou implementar páginas de erro em Kubernetes sem visão. Isso muda o jogo: agora, desenvolvedores e empresas que priorizam abertura e custo controlado têm uma alternativa viável para tarefas que antes exigiam acesso a modelos fechados.
Ao contrário de DeepSeek R1, que foi um salto técnico mas ainda dependia de arquiteturas mais simples, GLM-5.2 combina alta capacidade de contexto, baixa latência e custo competitivo. Sua performance em PosttrainBench, onde supera Opus 4.8, e em FrontierSWE, onde fica só atrás de Opus 4.8, mostra que a distilação não foi apenas cópia, foi otimização. Ainda assim, a ausência de visão e a alta taxa de tokens gerados limitam seu uso em fluxos reais. Mas o que importa é que, pela primeira vez, a China não está tentando alcançar a fronteira: ela está competindo nela.
Por que isso importa
GLM-5.2 força uma reavaliação do que significa 'modelo aberto'. Antes, aberto significava acessível, mas inferior. Agora, significa acessível e quase tão bom quanto os melhores. Isso pressiona empresas como OpenAI e Anthropic a repensar seus modelos de licenciamento e custo. Se GLM-5.2 já está perto de Opus 4.8 em tarefas de engenharia de software, o que acontece quando o próximo modelo, GLM-5.3, for treinado do zero? Além disso, sua capacidade de manter personalidade coerente em longas conversas, algo raro em modelos abertos, sugere que a cultura de treinamento chinesa está evoluindo para priorizar consistência e profundidade, não só velocidade. Isso pode ser o início de uma nova era de modelos abertos que não apenas replicam, mas inovam em padrões de interação.
Linha do tempo
GLM-5.2 é lançado como o novo melhor modelo aberto, superando GPT-5.4 em benchmarks e se posicionando como o primeiro modelo chinês aberto a competir diretamente com a fronteira ocidental.
Perguntas frequentes
GLM-5.2 é realmente melhor que GPT-5.4?
Sim, em vários benchmarks de desempenho puro. Em FrontierSWE e PosttrainBench, ele supera GPT-5.4. Em Vals.ai, fica em 5º lugar geral, atrás apenas de modelos fechados. Mas isso não significa que ele é melhor em tudo: em tarefas criativas ou de visão, ainda fica atrás. O que ele faz bem é raciocínio lógico, codificação e análise de contexto longo, com custo mais baixo que os modelos de ponta.
Por que a distilação de Claude importa?
Distilação significa que GLM-5.2 foi treinado para imitar as respostas de Claude Opus, não para aprender diretamente dos dados originais. Isso explica por que ele tem o 'tom' do Claude e se comporta como se fosse um modelo ocidental. Mas também significa que ele pode falhar em tarefas fora do padrão, como perguntas inesperadas ou situações raras. Ele é excelente no que foi ensinado, mas menos flexível que modelos treinados do zero.
GLM-5.2 tem visão? Posso usá-lo para analisar imagens?
Não. GLM-5.2 é exclusivamente um modelo de texto. A ausência de capacidade multimodal é sua maior limitação prática. Muitos usuários esperavam que um modelo da China avançasse nessa área, como o Qwen-VL ou o Kimi, mas GLM-5.2 focou apenas em otimizar desempenho textual. Isso o torna menos útil para aplicações como análise de documentos escaneados ou interfaces visuais.
Vale a pena usar GLM-5.2 em produção?
Se você precisa de um modelo aberto com alto desempenho em raciocínio e codificação, sim. Empresas já o usam para gerar dashboards, debugar código em Kubernetes e responder consultas técnicas complexas. Mas não é ideal para tarefas de alto volume por causa do custo de tokens e da ausência de visão. Se você já usa GPT-4 Turbo ou Claude 3.5, ele só vale se priorizar abertura, custo controlado ou evitar dependência de fornecedores ocidentais.
Fontes
- thezvi.wordpress.comfonte original
- Categoria
- CEVIU IA
- Publicado
- 23 de junho de 2026
- Editoria
- CEVIU IA