DFlash e Spec V2 revolucionam a speculative decoding com ganhos de throughput expressivos
Aprofundamento CEVIU
Aprofundamento
O DFlash não é só mais um drafter: é uma mudança de paradigma na decodificação especulativa. Enquanto EAGLE-3 e MTP nativos (como os do Gemma 4) ainda geram rascunhos sequencialmente, mesmo que no modelo menor , , o DFlash usa difusão em bloco para produzir 16 tokens de uma vez, com um único forward pass. Isso elimina o gargalo de latência intrínseco à autoregressão no draft, tornando o processo verdadeiramente hardware-friendly em B200s e TPUs.
A injeção de KV do modelo alvo no drafter é o segundo salto técnico. Diferente de métodos anteriores que usam features do alvo só na entrada do drafter (como o Medusa ou EAGLE), o DFlash injeta representações ocultas diretamente nos caches KV de cada camada do modelo rascunho. Isso mantém a condição forte ao longo da geração, e explica por que aceitação média sobe mesmo com drafters mais profundos. Não é só mais rápido: é mais preciso por design, sem trade-off entre speed e quality.
O que mudou
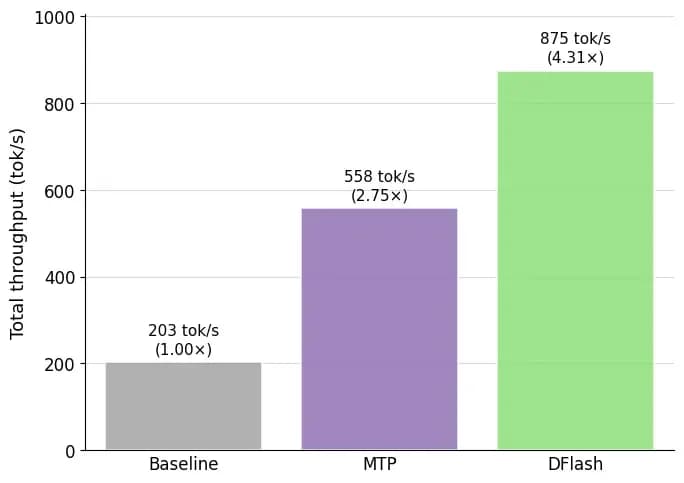
Em maio, a cobertura CEVIU tratava de MTP como o estado da arte, com acelerações de até 3x no Gemma 4 e ganhos de 1.8x em rollouts de RL. Agora, em junho, o DFlash + Spec V2 entrega >4.3x no Qwen 3.5 397B-A17B, superando até essa nova geração de MTP nativa. O que era rumor sobre 'injeção de contexto' virou código concreto no SGLang V2; o que era benchmark teórico em GPU A100 virou produção real em B200 com 8 TB/s de largura de banda HBM3e. E o Xiaomi MiMo v2.5-Pro-UltraSpeed já está usando isso em escala: 1.200 tps em modelo de 1T de parâmetros, algo impensável com MTP puro.
Por que isso importa
Isso não é otimização incremental. É a primeira vez que uma técnica de speculative decoding atinge eficiência próxima ao limite físico de hardware moderno: aproveita plenamente o throughput FP4 do B200 (9.000 TFLOPS) e reduz sincronizações host-device ao mínimo viável. Para operadores de LLMs, significa cortar custos de inferência em até 60% em workloads de baixa latência, como agentes interativos ou APIs de tempo real. Para desenvolvedores de modelos, abre espaço para usar arquiteturas maiores (como o Qwen 3.5 com 262k de contexto) sem pagar o preço usual em throughput. A barreira não é mais o modelo, mas a infraestrutura, e agora ela está sendo quebrada.
Linha do tempo
CEVIU reporta uso de decodificação especulativa em rollouts de RL com ganho de throughput de até 1.8x
CEVIU cobre lançamento de drafters MTP para Gemma 4 com aceleração de até 3x
CEVIU destaca TokenSpeed, motor de inference otimizado para workloads de agentes
Lançamento oficial do DFlash e Spec V2 pelo consórcio Z Lab, Modal e SGLang
Publicação da notícia atual com benchmarks em Qwen 3.5 397B-A17B e B200
Perguntas frequentes
DFlash funciona apenas com Qwen 3.5 ou pode ser adaptado a outros modelos?
Funciona com qualquer LLM baseado em Transformer. A Z Lab já disponibilizou drafters para Qwen 3-8B, Gemma 4 e DeepSeek-V4 no Hugging Face. O treinamento exige apenas acesso aos pesos do modelo alvo e um dataset pequeno de saídas, não é necessário re-treinar o modelo principal.
Qual é a diferença prática entre Spec V1 e Spec V2 no SGLang?
O V1 sincroniza o host com a GPU em cada etapa do ciclo de verificação. O V2 usa overlap scheduling: enquanto a GPU processa o lote N, o host já aloca KV para N+1 e limpa metadados do lote N-1. Isso eliminou 33% do overhead, e foi essencial para que o DFlash entregue seu potencial completo.
Por que o DFlash tem vantagem sobre MTP nativo, se ambos preveem múltiplos tokens?
MTP nativo ainda depende da estrutura autoregressiva do próprio modelo, ele 'desenrola' internamente os tokens, consumindo ciclos de GPU e memória. O DFlash é um modelo separado, leve e paralelo: gera o bloco inteiro em um único passo, com custo fixo independente do tamanho do bloco. Isso escala melhor em concorrência alta e modelos gigantes.
É possível usar DFlash sem o SGLang?
Sim, mas com esforço extra. O DFlash já tem suporte oficial no vLLM v0.20.1+. No entanto, o Spec V2 com overlap scheduling e injeção KV otimizada está exclusivo no SGLang, e é onde os ganhos de 4.3x foram medidos. Para produção, o stack completo (Z Lab + Modal + SGLang) é o caminho mais direto.
Fontes
- lmsys.orgfonte original
- Categoria
- CEVIU IA
- Publicado
- 16 de junho de 2026
- Editoria
- CEVIU IA