Uma taxonomia para arquiteturas de storage/workload
Aprofundamento CEVIU
Aprofundamento
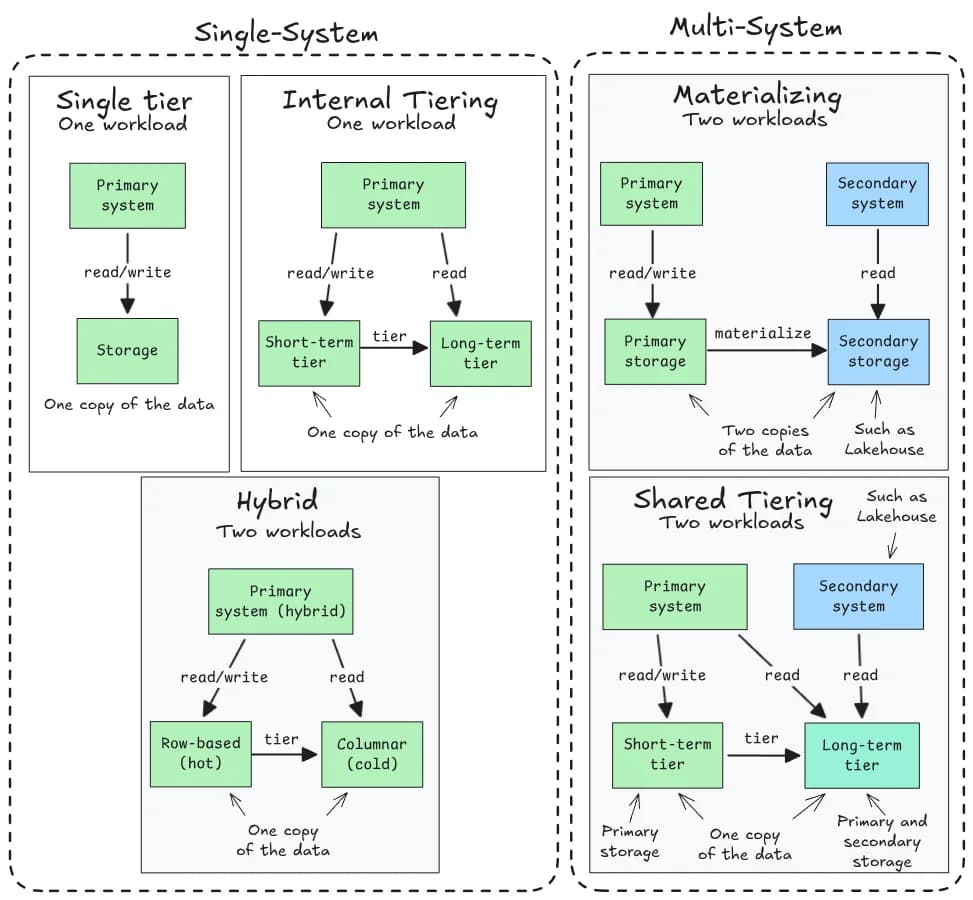
Arquiteturas de armazenamento modernas estão cada vez mais difíceis de classificar com rótulos tradicionais como OLTP ou OLAP. A proposta de taxonomia baseada em número de sistemas, workloads, visibilidade dos dados e cópias duráveis traz clareza técnica para um ecossistema fragmentado. Em vez de encaixar tudo em HTAP ou lakehouse, o modelo distingue cinco categorias principais: Single Tier, Internal Tiering, Hybrid, Materializing e Shared Tiering.
Cada categoria reflete decisões concretas de engenharia. Single Tier é o caso clássico de sistema único, como Postgres rodando em disco local. Internal Tiering adiciona camadas de custo eficiente dentro do mesmo sistema, como Kafka movendo dados do SSD para S3. Já o modelo Hybrid representa verdadeiros HTAPs, com SingleStore e TiDB como exemplos reais que combinam row-store e column-store no mesmo motor, com consistência gerida via merge-on-read ou replicação síncrona.
Por que isso importa
Essa taxonomia ajuda times de dados a escolher arquiteturas com critérios técnicos, não buzzwords. Muitos sistemas se dizem "unificados", mas na prática exigem duplicação de dados ou atraso na disponibilidade analítica. Com esse framework, é possível questionar: quantos sistemas estão envolvidos? Quantas cópias duráveis existem? Quando os dados ficam visíveis para análise?
Isso impacta governança, latência e custo. Um pipeline que copia dados de um banco transacional para um data warehouse (Materializing) tem dois pontos de falha e políticas de retenção independentes. Já o Shared Tiering, como no caso do Fluss ou supostamente LTAP, reduz cópias duráveis ao usar o lakehouse como camada fria compartilhada, mas ainda assim impõe atraso na visibilidade dos dados mais recentes. Clareza na arquitetura evita surpresas operacionais.
Linha do tempo
Publicação da taxonomia para arquiteturas de storage/workload, introduzindo categorias como Shared Tiering e diferenciando HTAP de LTAP
Perguntas frequentes
Qual a diferença entre HTAP e LTAP nessa taxonomia?
HTAP é um único sistema que suporta dois workloads (transacional e analítico), com mecanismos internos para manter consistência entre row-store e column-store. LTAP envolve dois sistemas distintos, onde o analítico (como um lakehouse) atua como camada fria compartilhada. A principal diferença é que HTAP tem visibilidade imediata dos dados em ambos os workloads, enquanto LTAP é assíncrono e depende da migração de dados entre camadas.
O que conta como 'cópia durável' na prática?
Cópia durável é qualquer gravação persistente em armazenamento não volátil, independente do sistema. Caching em memória não conta. No modelo Materializing, há duas cópias duráveis, uma em cada sistema. Já no Shared Tiering, só existe uma cópia, pois o dado quente fica em um sistema e o frio é acessado por ambos. O número real de cópias afeta custo, consistência e complexidade de backup.
Por que o 'zero-copy' é mais marketing que realidade?
Muitos sistemas anunciam 'zero-copy' quando na verdade ainda mantêm dados duplicados em cache ou em formatos diferentes. O importante não é o número exato de cópias, mas entender onde os dados estão, quanto tempo demora para ficarem visíveis e qual o custo operacional disso. Focar apenas em 'cópias' ignora dimensões críticas como frescor, modelo de dados e SLAs de recuperação.
Fontes
- jack-vanlightly.comfonte original
- Categoria
- CEVIU Dados
- Publicado
- 25 de junho de 2026
- Editoria
- CEVIU Dados