Como construir índices eficientes em lagos de dados dinâmicos com Apache Hudi
Aprofundamento CEVIU
Aprofundamento
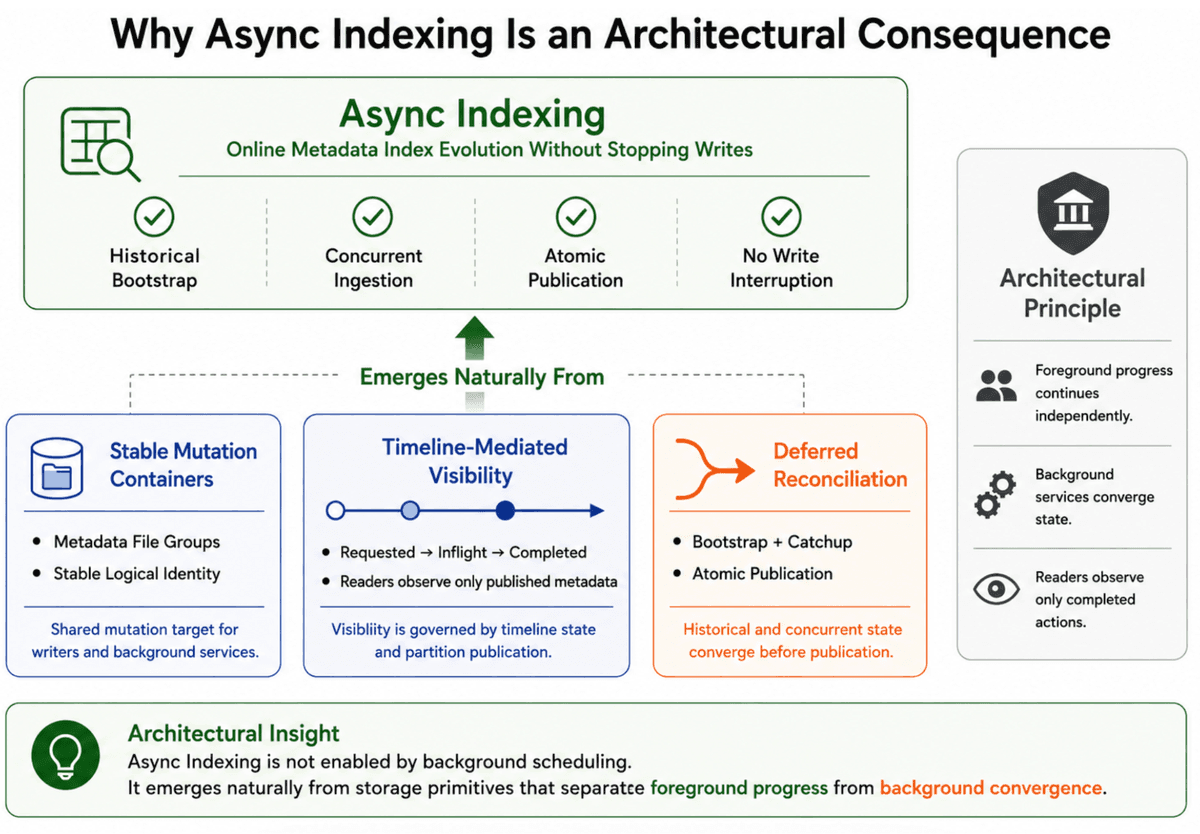
Hudi não é só uma biblioteca para upserts em data lakes, é um sistema construído desde 2017 com um modelo de mutação append-first como pedra angular. Isso permite algo que nenhum outro formato lakehouse (Iceberg, Delta) consegue no nível de especificação: adicionar índices novos, como bloom filters, índices de expressão ou estatísticas de coluna, em tabelas já em produção, sem parar escritas nem expor estado inconsistente. O segredo está em três primitivas arquitetônicas derivadas do Merge-On-Read: grupos de arquivos como contêineres lógicos estáveis, ações de indexação como eventos de primeira classe na linha do tempo (timeline), e um ciclo de vida de duas fases para partições de metadados (inflight → ativo). Essas peças não foram adicionadas depois; elas emergiram da decisão original de tratar mutação como um fluxo contínuo, não como reescritas.
O artigo atual detalha o 'catchup', a reconciliação entre o estado histórico que o índice inicializa e as escritas concorrentes que acontecem durante o bootstrap. Esse passo não é um workaround: é a materialização explícita da ideia de que o índice é um subproduto derivado, não uma cópia sincronizada. É por isso que Hudi pode oferecer indexação assíncrona em escala real, enquanto Iceberg e Delta ainda dependem de locks globais ou de indexação vinculada à escrita, o que bloqueia retroatividade e escalabilidade.
O que mudou
Em junho de 2026, a cobertura CEVIU já havia explicado por que os metadados precisam ser amigáveis à mutação documentação de Hudi, destacando a tabela de metadados (MDT) como um sistema append-first com compactação diferida. Agora, a nova postagem do Hudi mostra que essa arquitetura foi levada até o fim: não só os metadados são mutáveis, mas novos índices podem ser injetados *dinamicamente* em tabelas existentes. Antes, a MDT era vista como uma camada estática de otimização. Hoje, ela se revela um sistema evolutivo, onde cada novo índice (record_index, expression_index, bloom_filter) é uma extensão atômica da timeline, não uma operação de manutenção offline.
Por que isso importa
Para engenheiros de dados que operam pipelines de ingestão contínua em escala petabyte, interromper escritas para criar um índice não é apenas inconveniente, é inviável. A capacidade de adicionar um índice secundário para acelerar consultas de análise sem derrubar o pipeline muda a equação de governança: agora é possível iterar em estratégias de indexação conforme os padrões de leitura evoluem, não apenas no momento da criação da tabela. Isso também impacta diretamente a qualidade dos dados, índices de estatísticas de coluna ou sketches probabilísticos (como os citados em nossa cobertura anterior sobre data sketches documentação de Hudi) podem ser incorporados *após* a produção, sem exigir reprocessamento completo.
Repositório oficial: apache/hudi
Linha do tempo
CEVIU analisa a arquitetura de três camadas do Apache Iceberg, contrastando sua imutabilidade com modelos mais flexíveis.
CEVIU publica guia sobre tradeoffs de índices em bancos de dados, destacando o custo de escrita versus ganho de leitura.
CEVIU explora tradeoffs de índices vetoriais no Postgres, reforçando a importância de escolhas de indexação alinhadas ao workload.
CEVIU explica por que a tabela de metadados do Hudi precisa ser append-first para suportar alta mutação.
Hudi lança postagem detalhando indexação assíncrona em tempo real, comprovando a viabilidade prática do modelo arquitetônico descrito anteriormente.
Perguntas frequentes
Hudi realmente não para escritas durante a criação de um novo índice?
Sim. Enquanto o índice é construído, os writers continuam fazendo commits normais. Eles roteiam automaticamente novas mutações para os grupos de arquivos do índice em construção, graças ao mecanismo de file groups estáveis. Não há lock global, buffer infinito nem janela de troca.
Por que Iceberg e Delta não conseguem fazer isso mesmo sendo formatos maduros?
Porque ambos usam um modelo Copy-On-Write (COW) como base. Em COW, não existe um canal de append para índices em construção, toda atualização exige reescrita de arquivos. Isso força soluções como 'bootstrap-and-swap', que impõem janelas de indisponibilidade e risco de falha irreversível durante o replay.
Quais tipos de índice já são suportados com indexação assíncrona no Hudi?
Atualmente incluem record-level index (para upserts rápidos), bloom filters (para filtragem eficiente), column stats (min/max/contagem), partition stats, secondary index (baseado em colunas não-chave) e expression index (para consultas com funções personalizadas). Todos podem ser adicionados em tabelas existentes.
Essa funcionalidade está disponível desde qual versão do Hudi?
Foi introduzida oficialmente na versão 1.2.0, alinhada com a RFC-45. O código está no repositório oficial [[LINK:official_repository|Hudi no GitHub]] e documentado na seção de metadata table da documentação [[LINK:official_documentation|documentação de Hudi]].
Links relacionados
Fontes
- hudi.apache.orgfonte original
- Categoria
- CEVIU Dados
- Publicado
- 03 de julho de 2026
- Editoria
- CEVIU Dados