Elasticsearch como camada de memória persistente para agentes: arquitetura multi-índice com isolamento de tenants
Aprofundamento CEVIU
Aprofundamento
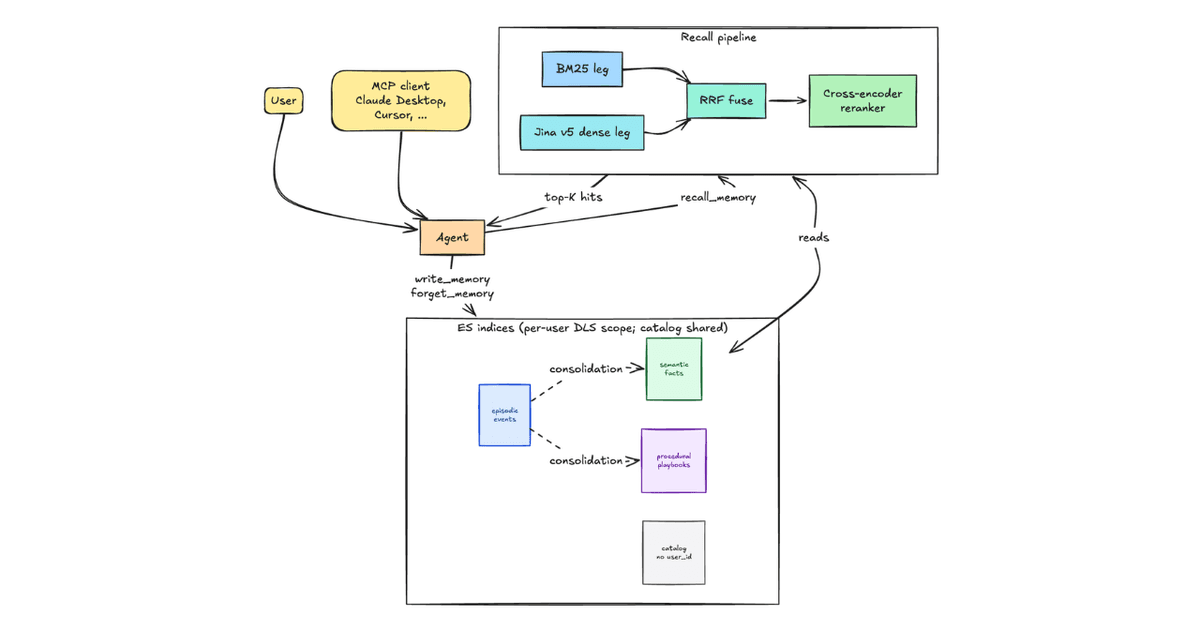
Elasticsearch não é só um motor de busca: virou uma infraestrutura de memória agentic com semântica de engenharia de software. A arquitetura multi-índice (episódico, semântico, procedural) não é só uma analogia cognitiva, é um contrato de API entre o agente e a camada de persistência. Cada índice tem regras explícitas de escrita, envelhecimento e supersessão, com campos como success_count, superseded_by e supporting_episode_ids que transformam documentos em objetos com comportamento, não apenas dados. Isso muda o jogo para DX: não há mais necessidade de orquestrar vetores, grafos e audit logs em três serviços distintos. Tudo roda sob um único DLS (Document Level Security), com recall híbrido RRF + cross-encoder já pré-configurado no pipeline nativo do Elasticsearch.
O verdadeiro salto técnico está na operacionalização da memória como código. O Agent Builder, agora em GA desde janeiro de 2026, não é um wrapper, é uma extensão da engine de busca. Ele converte chamadas de ferramentas em queries Elasticsearch com escopo de tenant embutido, aplica decay automático por timestamp nos índices episódicos e injeta pre-recall com a mensagem original do usuário para evitar perda de termos literais (versões, códigos de erro). E isso tudo sem depender de LLMs intermediários para filtragem ou deduplicação, o sistema usa BM25 + Jina v5 + Jina v2 num fluxo otimizado para latência sub-15ms, mesmo com quantização BBQ ativa.
O que mudou
A CEVIU já havia coberto alternativas como ApertureDB (abr/2026), RushDB 2.0 (mai/2026) e Redis Iris (mai/2026), mas todas exigiam composição de camadas: gráfico + vetor + auth + auditoria. O que mudou agora é a consolidação técnica: Elasticsearch entrega memória persistente com isolamento de tenant, supersessão com rastreamento de cadeias e recall híbrido nativo, tudo em uma única stack. Antes, a memória era um padrão conceitual (files, memory blocks, skills); agora é um contrato executável. O Agent Builder não só implementa os três tipos de memória descritos em nosso artigo de 28/abr, mas os torna observáveis, testáveis e integráveis com Elastic Workflows, algo que nenhum dos sistemas anteriores oferecia com essa granularidade de controle sobre o ciclo de vida do dado.
Por que isso importa
Para devs, isso significa menos infraestrutura para manter e mais tempo para construir lógica de negócio. Não é só sobre performance: é sobre garantir que um agente de suporte saiba que o reset do hub falhou duas vezes, e que o cabo foi roído pelo cachorro, sem que esses fatos sejam perdidos no contexto ou apagados por overwriting acidental. A arquitetura resolve problemas reais de produção: esquecimento progressivo (via decay), contradições (via supersessão com classificação natural/harsh), e vazamento entre tenants (via DLS nativo, não via middleware). E faz isso com custo previsível: DiskBBQ reduz uso de RAM em 95%, permitindo escalar memória semântica para petabytes sem triplicar o orçamento de infraestrutura.
Linha do tempo
CEVIU cobre ApertureDB como solução de memória multimodal baseada em gráfico-vetor
CEVIU destaca falhas estruturais de agentes stateless e limitações da busca vetorial pura
CEVIU detalha os três padrões de memória mutável: Files, Memory Blocks e Skills
CEVIU analisa o lançamento do Redis Iris como Context Engine para agentes corporativos
CEVIU desmonta a ideia de 'memória mágica' e propõe pipeline de extração-armazenamento-retrieval
CEVIU apresenta RushDB 2.0 com integração Neo4j, MCP e discovery de ontologia
Elasticsearch lança arquitetura multi-índice para memória persistente de agentes com isolamento de tenants e recall preciso
Perguntas frequentes
Como o Elasticsearch evita o 'lost in the middle' sem depender do tamanho do contexto do LLM?
Ele não depende do contexto do LLM. Usa pre-recall com a mensagem original do usuário antes de qualquer processamento, então termos literais (como 'Lumio Hub v2' ou 'erro 0x4A') são preservados para BM25. Depois, o recall híbrido (RRF + reranker) recupera fatos relevantes diretamente do índice, não do prompt.
O que acontece quando um usuário corrige uma informação armazenada? É apagada?
Não. A versão antiga é marcada com superseded_by e superseded_at, ficando invisível para recalls normais, mas acessível para auditoria ou perguntas históricas como 'onde eu já morei?'. A nova versão entra com confiança total ou reduzida, dependendo da classificação da contradição (natural ou harsh).
Posso usar isso com meu próprio LLM local, sem depender de APIs externas?
Sim. O Agent Builder é agnóstico quanto ao modelo. A CEVIU já documentou casos com GPT-OSS rodando localmente, onde o Elasticsearch lida apenas com memória, retrieval e segurança, o LLM fica responsável só pela geração e consolidação, sem precisar gerenciar estado.
Como o sistema escala para milhares de usuários com isolamento rigoroso?
Cada documento tem um campo tenant_id (ex: chave de API do usuário), e todas as queries usam Document Level Security (DLS) nativo do Elasticsearch. Não há joins, não há middleware de roteamento, o filtro é aplicado na camada de busca, com zero impacto em latência mesmo em clusters com milhões de índices.
Fontes
- elastic.cofonte original
- Categoria
- CEVIU Web Dev
- Publicado
- 19 de junho de 2026
- Editoria
- CEVIU Web Dev