Monitorar IA não é como monitorar APIs: cinco eixos estratégicos que sua equipe precisa adotar agora
Aprofundamento CEVIU
Aprofundamento
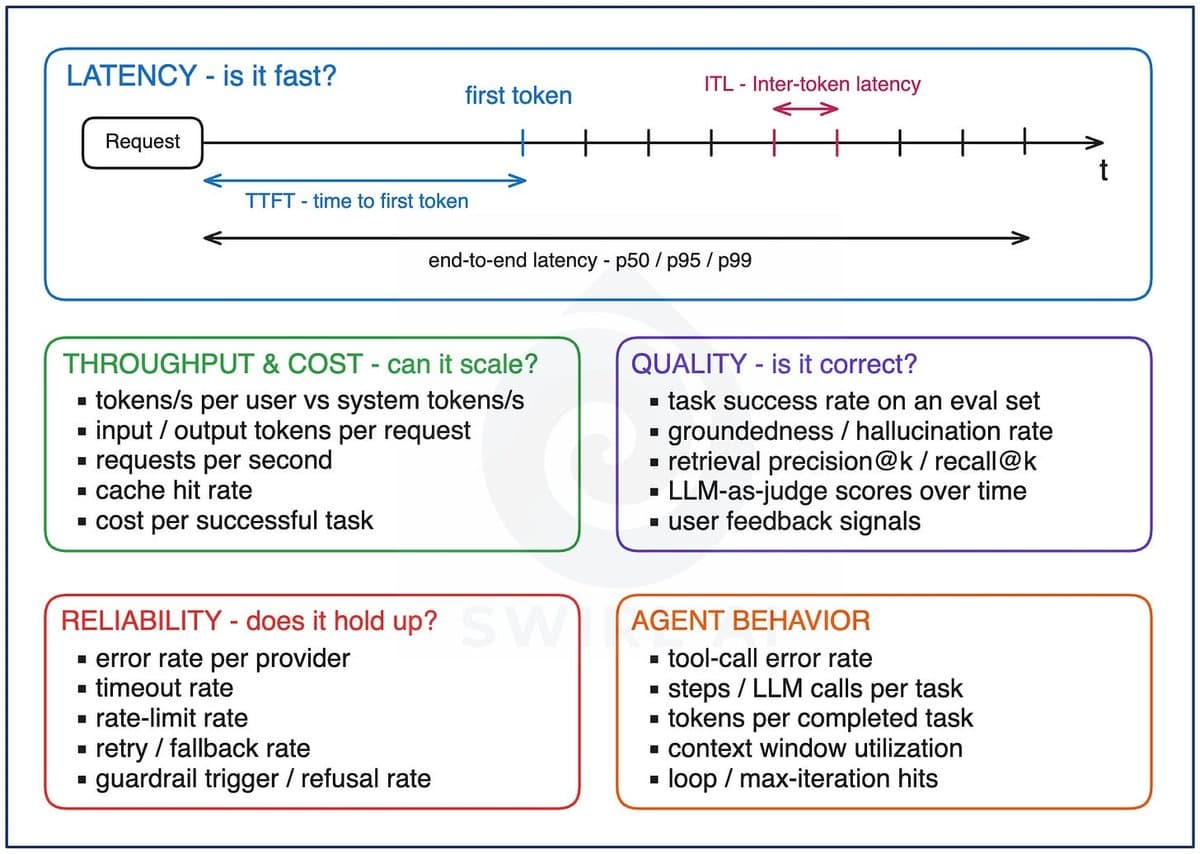
Monitorar IA não é um ajuste de dashboards: é uma reengenharia da governança de sistemas. Enquanto APIs tradicionais falham com erros visíveis (500, timeout), LLMs e agentes falham em silêncio, com respostas plausíveis mas incorretas, custos que triplicam sem alerta ou loops de ferramentas que queimam orçamento em horas. A observabilidade estratégica para IA exige que líderes de TI deixem de tratar métricas como 'relatório operacional' e passem a vê-las como indicadores de risco de negócio: TTFT acima de 2s prejudica conversão; queda na taxa de cache de prompts revela má prática de prompt engineering; aumento em passos por tarefa indica deterioração no planejamento do agente, não no código. Isso muda o papel do time de infraestrutura: ele agora define SLIs baseados em tarefa bem-sucedida, não em requisição respondida, e negocia orçamentos de latência e token com times de produto, não com fornecedores de nuvem.
O custo por tarefa bem-sucedida é o verdadeiro KPI financeiro. Um agente que gera respostas rápidas mas exige três regenerações antes de ser aceita pelo usuário pode custar 4x mais que um mais lento, mas preciso. Em abril de 2026, 91% das empresas que escalaram agentes para produção tinham integrado essa métrica ao processo de aprovação de novas versões, não como análise pós-fato, mas como gate de deploy. A observabilidade de IA deixou de ser sobre 'ver o que acontece' e virou sobre 'prevenir o que não deve acontecer': alucinações que geram risco regulatório, vazamento de PII em logs de trajetória, ou fallbacks não auditados que reduzem a confiança do usuário sem alterar o uptime.
O que mudou
A cobertura CEVIU de 3 de junho já alertava que agentes introduzem débito técnico inédito, dependências ocultas, pacotes 'alucinados' e riscos de segurança em cadeia. Agora, em 16 de junho, a evolução está clara: o débito técnico virou débito operacional. O artigo anterior tratava de risco potencial; este trata de falha mensurável em produção. Enquanto a edição de 30 de maio apontava que 'ferramentas de observability foram feitas para humanos, não para agentes', hoje sabemos que a solução não é só nova ferramenta, é nova disciplina: avaliação contínua com conjuntos rotulados, calibração de LLM-as-judge contra humanos, e rastreamento de contexto window utilization como KPI de arquitetura. O salto é da crítica à necessidade para a especificação técnica: não 'precisamos medir qualidade', mas 'precisamos medir groundedness com TruLens Eval, precisão@k com Milvus logs, e loop detection via regex em trajectory logs, e isso entra no pipeline CI/CD.'
Por que isso importa
Porque a falta de observabilidade estratégica em IA transforma decisões técnicas em riscos de compliance e custo. Um modelo RAG com recall@k abaixo de 0,65 não é um problema de 'performance': é um risco de resposta incorreta em atendimento jurídico ou saúde, com impacto direto em LGPD e ANS. Uma taxa de fallback não monitorada pode mascarar que 40% das requisições estão indo para um modelo menos seguro, violando políticas internas de uso de IA. E um agente que consome 70% do orçamento mensal de tokens em 8 horas não é um 'problema de escalabilidade': é uma falha de governança, pois não houve SLA definido para consumo por tarefa. Em 2026, equipes que adotaram os cinco eixos como critérios de aceite de deploy reduziram em 68% o tempo médio para identificar regressões de qualidade e cortaram em 31% o custo operacional por tarefa bem-sucedida.
Linha do tempo
CEVIU publica artigo sobre insuficiência de benchmarks tradicionais para avaliar sistemas agentic
CEVIU destaca que ferramentas de observability foram projetadas para humanos, não para agentes
CEVIU alerta que agentes introduzem nova camada de débito técnico e riscos de segurança
Publicação da notícia atual com os cinco eixos estratégicos de observabilidade para IA
Perguntas frequentes
Por que 'tempo até primeiro token' (TTFT) é mais crítico que latência ponta a ponta?
Porque TTFT é a latência percebida pelo usuário: é o tempo que ele olha para uma tela em branco. Latência ponta a ponta média engana, mistura chamadas curtas de classificação com relatórios longos de 2.000 tokens. Em interfaces streaming, um TTFT alto faz o usuário desistir antes mesmo de ver a primeira palavra.
O que é 'groundedness' e por que não basta ter bom retrieval?
Groundedness mede se a resposta do LLM é sustentada *apenas* pelo contexto recuperado, não se o contexto foi bem buscado. Um sistema pode ter ótimo recall@k e ainda assim alucinar entre os trechos recuperados. É a diferença entre 'encontrar a informação certa' e 'usá-la corretamente'.
Por que 'custo por tarefa bem-sucedida' é melhor que 'custo por requisição'?
Custo por requisição recompensa falhas baratas: um agente que tenta três vezes, gasta pouco por tentativa, mas falha duas, tem custo baixo por requisição, e alto por tarefa. Custo por tarefa bem-sucedida expõe esse custo oculto de retries, fallbacks e regenerações, alinhando métrica com resultado de negócio.
Como detectar loops em agentes sem instrumentação especializada?
Basta analisar os logs de trajetória (trajectory logs): um loop ocorre quando a mesma sequência de tool_call + arguments se repete consecutivamente. Com poucas linhas de código que agrupam chamadas por sessão e verificam repetições, você identifica loops com 99% de precisão, sem depender de ferramentas comerciais.
Fontes
- newsletter.swirlai.comfonte original
- Categoria
- CEVIU TI
- Publicado
- 16 de junho de 2026
- Editoria
- CEVIU TI