Ciência ou velocidade: que tipo de experimentador você é?
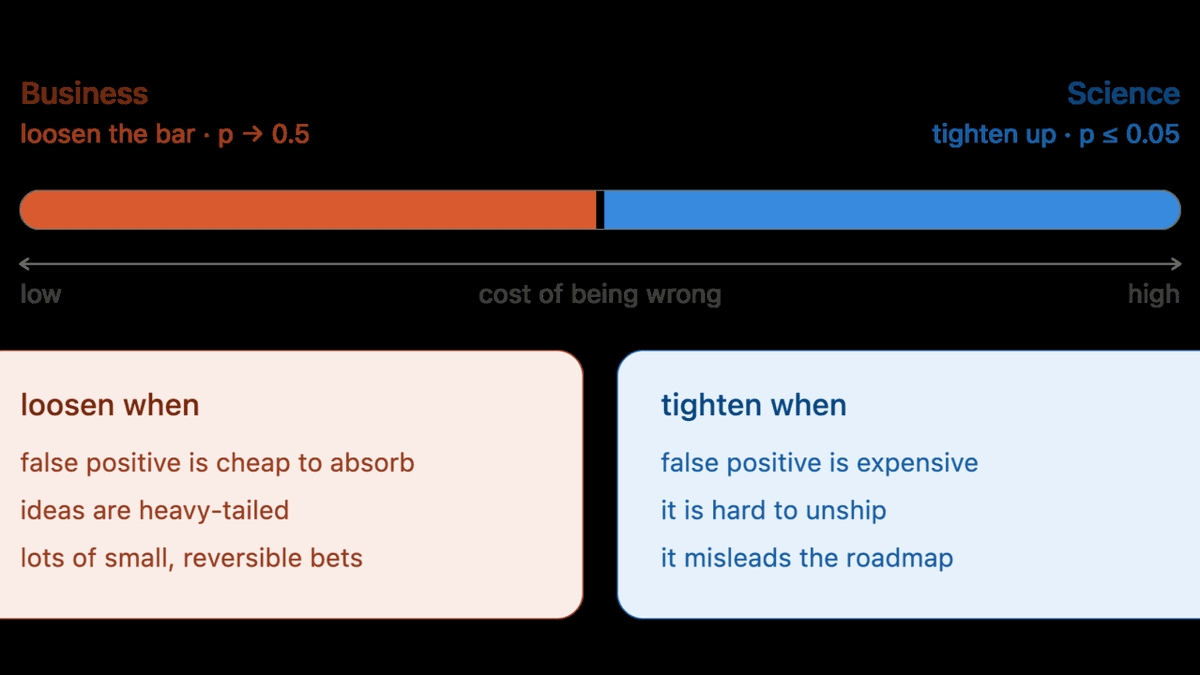
Existem dois tipos de experimentadores: os que otimizam para certeza científica e os que otimizam para velocidade de negócio. Regras rígidas de significância, como p < 0,05, foram criadas para evitar falsos positivos, mas estudos em larga escala mostram que elas podem deixar mais de um quarto do valor na mesa e, em alguns casos, ficar abaixo até mesmo de não fazer nada. O ponto central não é o teste em si, e sim a decisão: muitas equipes travam discutindo resultados em vez de agir. Uma abordagem melhor é definir a intenção antes, seja provar superioridade, seja checar não inferioridade, e ajustar os limiares ao custo real de errar.
Aprofundamento CEVIU
Aprofundamento
O artigo atual não é sobre estatística, é sobre como tomamos decisões sob incerteza em marketing digital. A grande armadilha? Tratar o p-valor como uma regra de ouro, quando ele é só um sinalizador técnico para uma escolha estratégica muito mais antiga: 'estou testando para provar que algo é melhor, ou para garantir que não vai piorar?'.
Na prática, isso muda tudo. Um teste de superioridade exige evidência forte (p < 0,05 faz sentido se você vai lançar um novo checkout com custo alto de reversão). Já um teste de não inferioridade, usado em 60% dos casos reais, segundo Georgiev, pergunta: 'essa mudança é tão boa quanto o controle, dentro de uma margem que eu aceito?' Aqui, p = 0,3 pode ser suficiente se o ganho colateral (ex: menos código para manter, tempo de carregamento 100ms menor) compensa um leve trade-off. O MIT/Stanford/Amazon mostrou que usar p < 0,05 cegamente deixa 25, 33% do valor potencial de fora. Netflix vai além: em cenários de alta velocidade e baixo custo de iteração, o p-valor ideal sobe para 0,5, ou seja, metade das vezes você espera que o resultado seja estatisticamente 'não conclusivo', mas ainda assim age.
Por que isso importa
Porque atraso na decisão é custo real. Uma equipe que discute por cinco dias se um teste com p = 0,07 'vale a pena' está perdendo janela de aprendizado, desgastando alinhamento e deixando métricas-chave (como CAC ou LTV) sem ajuste. O problema não está nos dados, mas na ausência de um contrato pré-teste: qual métrica é decisiva? Qual margem de perda é tolerável? O que é 'win', 'flat' e 'loss' para *esse* experimento específico? Sem isso, toda leitura vira negociação, e negociação em dados vira justificativa pós-fato.
Perguntas frequentes
Qual p-valor devo usar no meu programa de testes?
Não existe um número universal. Se seu time lança features caras e difíceis de reverter, mantenha p < 0,05 para testes de superioridade. Se está migrando para um novo CMS com impacto limitado em conversão mas ganho claro em performance e manutenção, use não inferioridade com margem de -2% e p < 0,2. O valor vem da sua curva de custo de erro, não do manual de estatística.
Como saber se um teste deve ser de superioridade ou não inferioridade?
Pergunte-se: 'Se esse teste der flat, o que eu faço?' Se a resposta for 'implemento mesmo assim, porque reduz custo operacional', é não inferioridade. Se for 'volto à prancheta', é superioridade. A regra simples: superioridade é para mudanças com alto custo de engajamento; não inferioridade é para otimizações com ganhos colaterais mensuráveis.
O que acontece se eu relaxar demais os critérios e acumular pequenas perdas?
É o risco de 'perda por deriva': cinco testes com variações 1% piores cada um geram queda cumulativa de 5% em conversão, sem que nenhum acione alarme. Por isso, não inferioridade exige definição clara da margem (ex: não pode cair mais de 1,5% em revenue per session) e revisão periódica do portfólio de testes, não só do individual.
Como convencer meu time a adotar essa abordagem?
Comece com um único teste de não inferioridade em uma melhoria técnica (ex: atualização de biblioteca JS que reduz bundle size). Defina antes: métrica principal (tempo de interação), margem aceitável (-0,8% em conversão), e ação para flat (implementar). Mostre que o resultado foi 'flat', e que, mesmo assim, o time ganhou 4h/semana de dev time. Isso constrói credibilidade prática, não teórica.
Fontes
- linkedin.comfonte original
- Categoria
- CEVIU Marketing
- Publicado
- 23 de junho de 2026
- Editoria
- CEVIU Marketing