LTV ajustado pelo compute: a nova métrica que startups de IA precisam dominar
Aprofundamento CEVIU
Aprofundamento
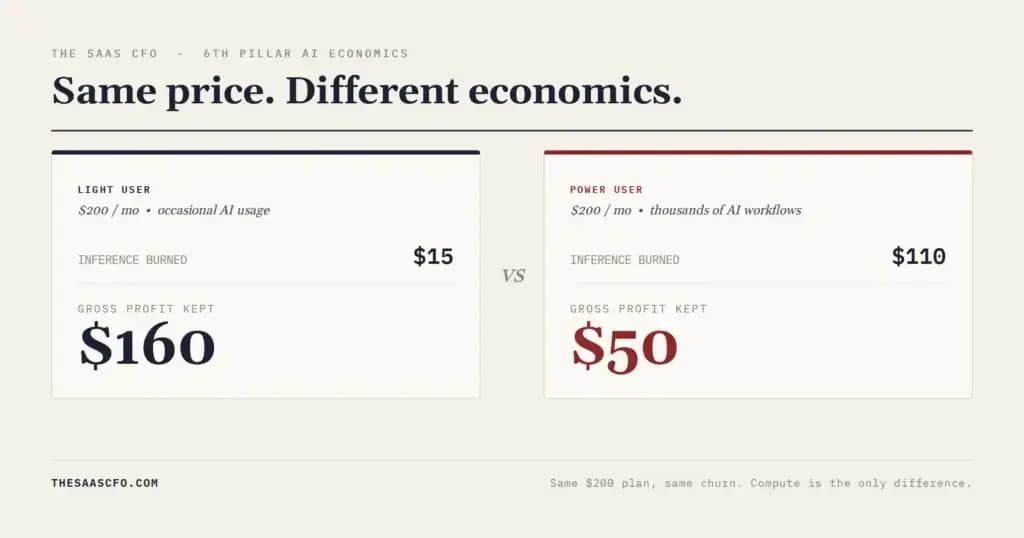
O LTV ajustado pelo compute não é só uma nova fórmula, é um sinal de que o modelo de negócios de IA está deixando de ser 'software com modelos embutidos' e virando uma operação de infraestrutura com camada de produto. Startups que ainda usam LTV tradicional como north star estão voando cego: duas empresas com o mesmo ARPA de R$ 200/mês podem ter margens brutas de 25% e 78%, dependendo de como os clientes usam os modelos. A métrica força o empreendedor a encarar uma verdade incômoda: seu 'cliente ideal' pode estar custando mais do que gera, especialmente se ele usa inferência pesada em GPUs A100 ou H100 sem trigger de cobrança adicional.
Isso muda a forma como você constrói o produto desde o dia 1. Não basta escolher entre 'subscription' ou 'usage-based': o certo é desenhar planos com 'compute allowances', 'model routing rules' (ex: GPT-4 para tarefas críticas, Phi-3 para rotinas) e 'fair-use thresholds' que atuam como guardrails automáticas. Empreendedores que ignoram isso acabam com CAC saudável, mas com churn silencioso, clientes que não cancelam, mas passam a usar menos porque percebem lentidão ou limitações não declaradas.
Por que isso importa
Porque o custo de escalar IA não é linear, é exponencial por cliente, não por receita. Enquanto um SaaS tradicional ganha eficiência com escala (mais clientes = menor custo por usuário), um produto de IA pode ter custo por cliente que dobra ao triplicar o uso de tokens. Isso transforma decisões de growth em jogos de equilíbrio: cada lead adquirido com foco em 'volume' pode virar um buraco financeiro se não houver controle granular de consumo. O LTV ajustado pelo compute vira o termômetro real da saúde unitária, e o primeiro alerta de que sua estratégia de precificação precisa de correção antes do prejuízo aparecer no P&L consolidado.
Perguntas frequentes
Preciso calcular isso se minha startup ainda está na fase de validação, com menos de 50 clientes?
Sim, especialmente nessa fase. É mais fácil ajustar pricing, planos e arquitetura de inferência com 30 clientes do que com 300. Se seus primeiros usuários já mostram variação de 5x no consumo de tokens, isso é um sinal forte de que seu modelo de receita não acompanha a curva de custo, e corrigir agora evita reengenharia cara depois.
Como faço para atribuir custos de infraestrutura (como Kubernetes, storage, rede) ao 'compute' de cada cliente?
Comece simples: aloque proporcionalmente ao uso de GPU-hours ou tokens processados. Ferramentas como Kubecost ou Datadog + custom metrics permitem rastrear isso por namespace ou label. Não busque perfeição, busque sinal. Se 80% da variação de custo vem da inferência, priorize essa medição primeiro.
Meu produto tem IA embutida, mas não é o principal diferencial. Preciso usar essa métrica?
Só se o custo de IA for >10% da receita por cliente e variar significativamente entre segmentos. Exemplo prático: um CRM com assistente de vendas baseado em LLM que consome 0,5 token por interação. Se seu cliente médio faz 200 interações/mês, e seu custo por token é $0,0003, o impacto é irrisório. Mas se ele roda 10 mil análises de call recordings por mês, o cálculo muda, e o LTV ajustado vira essencial.
Fontes
- thesaascfo.comfonte original
- Categoria
- CEVIU Empreendedores
- Publicado
- 17 de junho de 2026
- Editoria
- CEVIU Empreendedores