Netflix simplifica o batch compute com Kueue
Aprofundamento CEVIU
Aprofundamento
A Netflix trocou seu sistema interno de enfileiramento de jobs, o CMB, pelo Kueue, um componente open source do ecossistema Kubernetes. Isso não foi só uma troca de ferramenta, foi uma mudança de arquitetura: de um orquestrador customizado para um sistema que entende nativamente as primitivas do Kubernetes, como Pod e Job. O Kueue gerencia fila, prioridade e quota em nível de cluster, permitindo que a plataforma Titus deixe de cuidar de lógica de agendamento e se concentre em execução e federacao. A migração eliminou a necessidade de manter código próprio para fair share e preempção, que antes eram implementados de forma parcial e rígida no CMB.
Com o Kueue, a Netflix ganhou preempção real: jobs de baixa prioridade podem ser interrompidos para liberar recursos para os de alta prioridade, mesmo dentro de reservas de capacidade. Isso aumentou a utilização média de recursos sem sacrificar isolamento entre equipes. Ainda, a integração direta com o kube-scheduler evitou fragmentação de placement, algo crítico para manter eficiência em milhares de nós. A operação virou mais simples: um clique no UI transforma um tenant em ClusterQueue + LocalQueue, com conversão automática de quotas e flavors de recurso.
Por que isso importa
Para quem opera plataformas de containers em escala, essa migração mostra que é possível substituir sistemas internos complexos por componentes maduros do ecossistema Kubernetes sem perder funcionalidade, e com ganho de confiabilidade. O Kueue não exige substituir o scheduler, o que o torna compatível com plataformas que já têm lógica de placement própria, como Titus. Isso é um modelo para outras empresas que usam Kubernetes em camadas abstratas: não precisa reinventar a roda. Ainda, a abordagem de migração transparente, com rollout por tenant e rollback fácil, é um case de baixo risco que outras equipes podem replicar. A Netflix provou que, em batch compute, o open source não é só para startups, é a base para operações de ponta.
Linha do tempo
Netflix lança o Compute Managed Batch (CMB) como sistema interno de enfileiramento de jobs em batch.
Netflix conclui migração de milhões de jobs do CMB para o Kueue, encerrando o desenvolvimento do sistema customizado.
Perguntas frequentes
O que é Kueue e por que ele é diferente de YuniKorn ou Volcano?
Kueue é um sistema de enfileiramento para jobs no Kubernetes que não substitui o kube-scheduler. Ele atua como um controlador que gerencia filas, prioridades e quotas, deixando o agendamento real para o scheduler nativo. Já YuniKorn e Volcano substituem o kube-scheduler por completo, o que pode quebrar integrações existentes. Para a Netflix, isso foi crucial: manter o Titus Scheduler intacto evitou problemas de placement e conservou a eficiência de distribuição de carga.
Como a Netflix garantiu que a migração não afetaria os usuários finais?
Eles mantiveram a API do CMB inalterada. Os usuários continuaram enviando jobs da mesma forma, sem precisar mudar código ou fluxo. Por trás, o Titus roteava os jobs para células com Kueue habilitado, convertendo automaticamente tenants em ClusterQueues e LocalQueues. A transição foi feita por toggle no UI, um clique ativa o Kueue para um tenant, e se algo der errado, basta desligar para voltar ao CMB.
O que mudou na gestão de capacidade com Kueue?
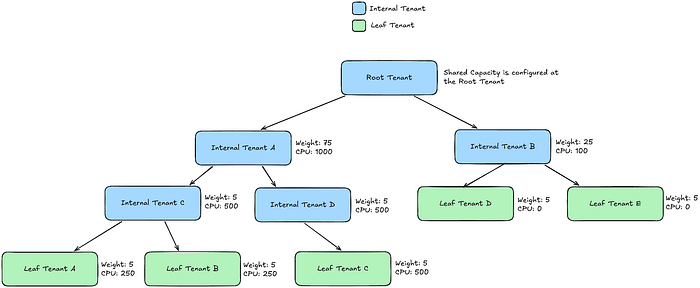
Antes, no CMB, a capacidade reservada era fixa: mesmo que não fosse usada, não podia ser emprestada. Com Kueue, a preempção permite que recursos reservados e ociosos sejam temporariamente usados por outros tenants, e recuperados assim que o dono precisar. Isso aumentou a utilização média sem perder garantias de isolamento. Além disso, quotas agora são aplicadas em tempo real, não só na admissão, como antes.
Por que a Netflix escolheu migrar o cliente mais complexo primeiro?
Migrar o maior e mais exigente cliente logo no início validou que o Kueue suportaria carga extrema, alta concorrência e configurações de prioridade delicadas. Se funcionasse para ele, funcionaria para todos. Isso reduziu risco e permitiu que a equipe ajustasse parâmetros de QPS e concorrência com base em dados reais, antes de escalar para milhares de outros tenants.
Fontes
- netflixtechblog.comfonte original
- Categoria
- CEVIU DevOps
- Publicado
- 24 de junho de 2026
- Editoria
- CEVIU DevOps