GKE Inference Gateway corta até 92% da latência em inferência de IA com cache de prefixo inteligente
Aprofundamento CEVIU
Aprofundamento
O GKE Inference Gateway não é só mais um load balancer: é uma camada de roteamento de inferência nativa do Kubernetes, construída em cima da Kubernetes Inference Extension (coberta pelo CEVIU em 10/06) e integrada ao llm-d, framework open-source da CNCF que agora está em GA com agendamento preditivo de latência. Ele opera no nível da Gateway API, lendo o prefixo textual da requisição, como instruções de sistema ou contexto RAG, e direcionando para o pod exato com o KV cache já carregado na RAM, SSD local ou até Google Cloud Storage, graças ao offloading hierárquico introduzido no llm-d v0.7 (maio/2026). Isso elimina a recomputação de tokens idênticos entre requisições, algo que o balanceamento round-robin tradicional fazia sistematicamente, derrubando taxas de acerto de cache de 80% para menos de 20% em cargas reais.
Na prática, isso muda a engenharia de plataformas: você não precisa mais escolher entre manter pods 'quentes' (custo alto) ou escalar sob demanda (latência alta). O Gateway gerencia o estado distribuído do cache como um recurso de primeira classe, com objetos personalizados como InferencePool e InferenceObjective, parte da prévia multi-cluster anunciada em março/2026. E, diferentemente de soluções como o vLLM + Inferact (cobradas no CEVIU em 03/06), essa é uma funcionalidade nativa do GKE, sem necessidade de operar proxy customizado ou ajustar manualmente políticas de roteamento no Envoy.
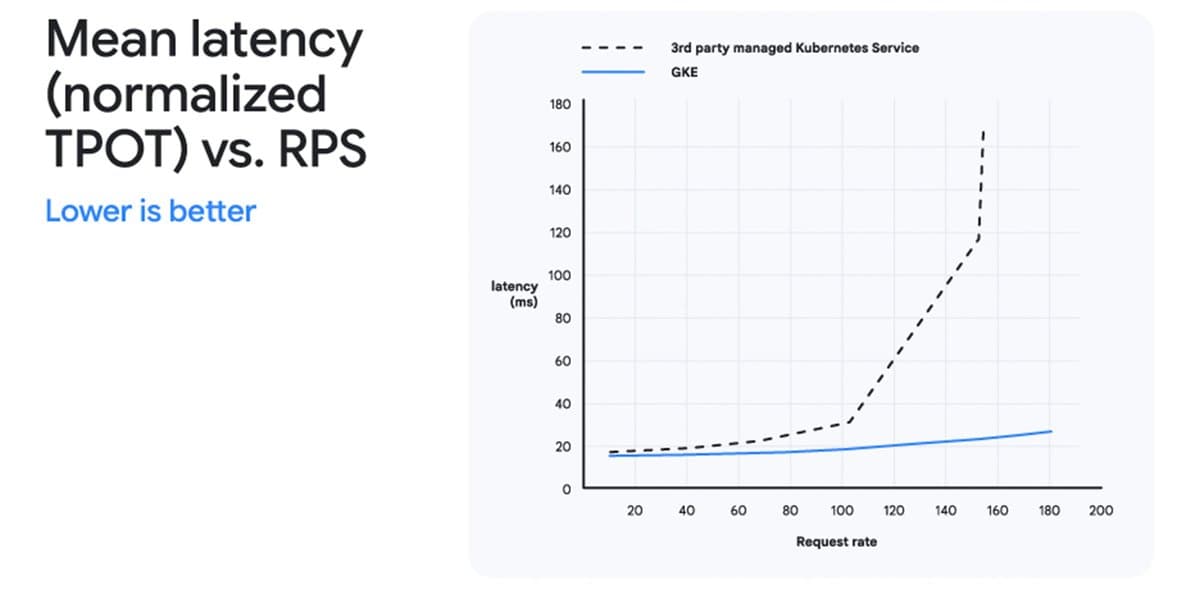
O que mudou
A cobertura anterior do CEVIU sobre roteamento ciente de cache (17/04 e 03/06) tratava de técnicas experimentais e soluções de terceiros, como vLLM com roteamento customizado ou extensões manuais da Gateway API. Agora, o GKE Inference Gateway traz isso como feature GA nativa, integrada ao ciclo de vida do cluster. O que era rumor em abril, 'roteamento baseado em estado do backend', virou realidade concreta com métricas mensuráveis: 92,8% menos TTFT, 83,9% menor latência na cauda (95º percentil) e redução de custos por token em até 25%. Também evoluiu desde a cobertura de 10/06: a Inference Extension agora tem suporte oficial para cache de prefixo inteligente, não apenas para estado de fila ou LoRA adapters, e isso foi validado em benchmark independente contra o EKS, não só em teoria.
Por que isso importa
Para times de DevOps e engenharia de plataformas, isso significa menos tempo gasto em tuning manual de HPA, menos dependência de proxies externos como Envoy ou Istio para roteamento especializado, e maior previsibilidade de custo em nuvem. Um único cluster GKE pode agora servir múltiplos LLMs com diferentes contextos estáticos (documentação, personas de chat, regras de compliance) sem duplicação de cache ou disputa por memória GPU. A combinação com GKE Pod Snapshots (novembro/2025) e Standby Buffers (06/06) forma uma stack completa de otimização de inferência: startup rápido de nodes, inicialização instantânea de pods e roteamento preciso de requisições, tudo dentro do mesmo modelo operacional do Kubernetes.
Linha do tempo
CEVIU analisa limitações do balanceamento round-robin para LLMs e aponta necessidade de roteamento ciente de cache
CEVIU mostra como DigitalOcean e Inferact cortaram custos de inference em até 4x com roteamento ciente de prefixo
CEVIU cobre a Kubernetes Inference Extension como base para roteamento baseado em estado do backend
Google lança GKE Inference Gateway em GA com cache de prefixo inteligente e integração com llm-d
Perguntas frequentes
O GKE Inference Gateway substitui o uso de vLLM ou llama.cpp?
Não. Ele opera na camada de rede, acima do runtime. Você ainda usa vLLM, llama.cpp ou qualquer outro servidor de inferência compatível com OpenAI API. O Gateway só decide *para qual pod* enviar cada requisição, com base no conteúdo do prompt, não executa o modelo.
Preciso mudar minha aplicação para usar o GKE Inference Gateway?
Não. A integração é transparente. Basta expor seu servidor de inferência como um Service com o label correto, instalar a Inference Extension e configurar uma InferenceGateway. Sua aplicação continua chamando o endpoint do Gateway como faria com qualquer outro load balancer.
Como funciona o cache de prefixo com prompts dinâmicos, como em chats multi-turn?
O Gateway identifica o prefixo estático (ex: sistema + regras de negócio) e o suffixo dinâmico (ex: pergunta do usuário). Ele roteia baseado no prefixo, mantendo o cache quente. O suffixo é processado normalmente, mas sem reprocessar os tokens repetidos, o que reduz drasticamente a latência inter-token.
O recurso está disponível em todos os clusters GKE?
Só em clusters com GKE version 1.30+ e Inference Extension ativada. Requer também o uso de GKE Autopilot ou Standard com configuração específica de node pool com GPUs/TPUs. Não funciona em clusters legados com versões anteriores à GA em setembro/2025.
Fontes
- cloud.google.comfonte original
- Categoria
- CEVIU DevOps
- Publicado
- 17 de junho de 2026
- Editoria
- CEVIU DevOps