Como o VS Code reduziu custos e latência no GitHub Copilot
Aprofundamento CEVIU
Aprofundamento
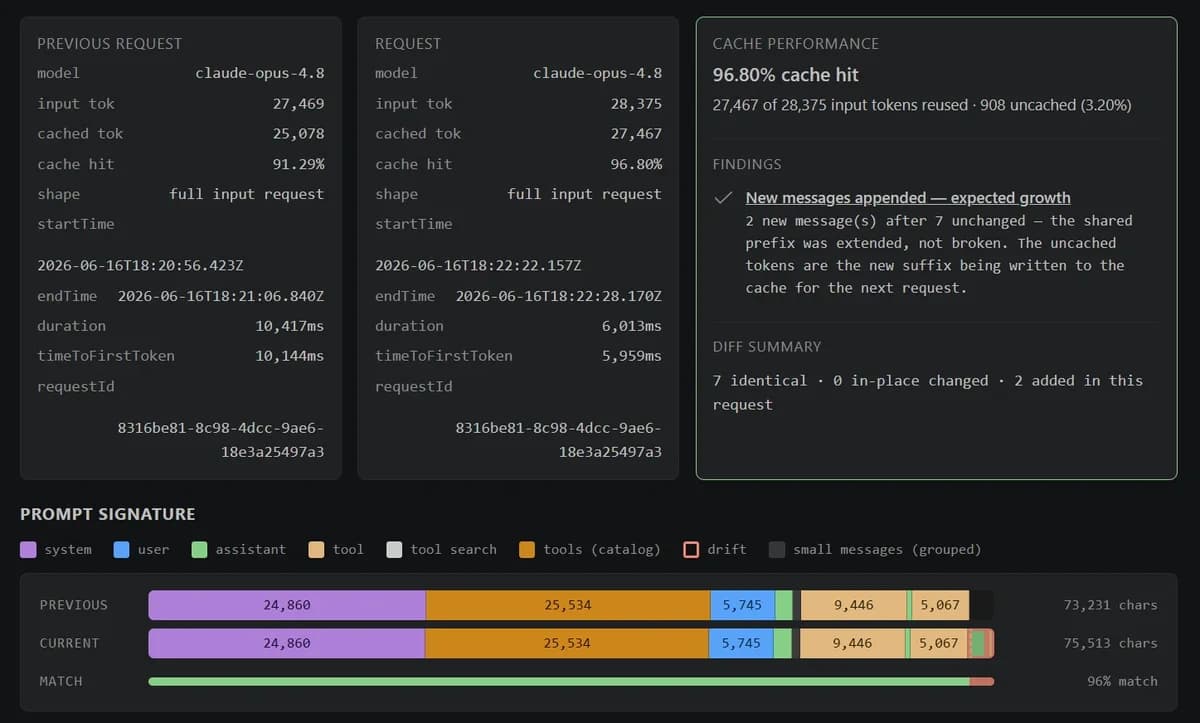
O VS Code não está só ajustando configurações: está redesenhando como agentes de IA operam em ambientes de desenvolvimento real. A otimização de tokens aqui não é sobre cortar palavras, é sobre reestruturar o ciclo de vida do contexto. O cache de prompts agora persiste até 24 horas em armazenamento GPU-local, não apenas nos 5, 10 minutos padrão. Isso muda a operação de sessões intermitentes: um dev que pausa por 30 minutos e retoma não paga por um cold start completo, porque o estado do modelo já está pré-carregado. Essa mudança exige adaptação na infraestrutura de inferência, mas traz ganhos mensuráveis, até 919% de aumento na taxa de acerto do cache para gaps longos.
A troca de HTTP por WebSockets não é só 'mais rápido'. É uma mudança arquitetural: cada chamada sequencial em uma sessão agente (ex: buscar referências → editar arquivo → executar teste) passa a reusar estado local da conexão, evitando overhead de handshake e serialização repetida. E o tool search com embedding-guided routing não é simples busca por nome, é uma consulta vetorial contra representações semânticas de ferramentas, feita inteiramente no cliente. Isso elimina latência de round-trip e permite descoberta dinâmica de ferramentas MCP adicionadas ou removidas durante a sessão.
O que mudou
Na cobertura anterior de 26/06, o CEVIU destacou o roteamento ciente de cache e o carregamento diferido como estratégias emergentes artigo original. Agora, essas ideias viraram produção: o prompt_cache_retention com valor '24h' está ativo no VS Code Stable; o tool search com defer_loading está habilitado nativamente em GPT-5.4+ e Claude 4+; e os WebSockets são o transporte padrão para modelos OpenAI GPT-5.2+ em todos os produtos Copilot. Também houve uma mudança operacional crítica: a migração do tool search para execução client-side, com embeddings locais, foi confirmada como rollout estável, algo ainda em experimentação no relato de 26/06.
Por que isso importa
Para equipes que usam Copilot em pipelines CI/CD ou em ambientes regulados, menor latência significa menos tempo de espera em tarefas críticas como análise de segurança ou geração de testes. Menor uso de tokens não é só economia: é maior previsibilidade de custos em orçamentos mensais de IA, especialmente com a faturação baseada em uso ativa desde junho. E o cache persistente de 24h reduz variações de desempenho entre sessões, um fator-chave para SREs que monitoram SLIs de tempo de resposta em assistência de código. Além disso, a descentralização da busca de ferramentas melhora a confiabilidade: não há dependência de atualizações síncronas entre servidor Anthropic e extensões locais.
Linha do tempo
Lançamento da orquestração multi-agente no VS Code 1.109, com suporte unificado para Anthropic e OpenAI
CEVIU aponta preocupação crescente com custos de workflows agentic no GitHub
Relatório Cursor mostra que maior uso de contexto com cache barato reduz custos totais
Copilot CLI passa a ser mais seletivo na delegação de tarefas entre agentes
Publicação oficial da Microsoft detalhando otimizações de eficiência de tokens no Copilot
CEVIU analisa o roteamento ciente de cache e carregamento diferido como estratégias emergentes
Implementação consolidada de cache de 24h, WebSockets padrão e tool search client-side no VS Code Stable
Perguntas frequentes
O que exatamente é 'prompt prefix caching' e por que ele reduz custos?
É o armazenamento do estado interno do modelo (tensores key/value) após processar a parte estável do prompt, como instruções de sistema, definições de ferramentas e histórico. Quando reutilizado, esse estado evita recalcular tudo do zero. Tokens de entrada em cache custam até 10 vezes menos que os não cacheados, segundo a política de precificação da OpenAI.
Qual é a diferença entre tool search server-side e client-side no Copilot?
No server-side, o modelo envia uma requisição para o provedor (OpenAI ou Anthropic), que faz a busca no catálogo remoto. No client-side, o VS Code executa a busca localmente usando embeddings próprios, sem depender de round-trip externo. Isso reduz latência e permite descobrir ferramentas MCP adicionadas durante a sessão.
Por que WebSockets melhoram a latência em sessões agentic, se HTTP/2 já permite conexões reutilizáveis?
HTTP/2 reutiliza a conexão, mas cada requisição ainda é um payload independente com headers e serialização. WebSockets mantêm um canal contínuo com estado compartilhado, o provedor pode reusar o estado da última resposta em memória local, eliminando overhead de inicialização em cada etapa da cadeia de chamadas de ferramentas.
O que acontece se o cache de prompts expirar durante uma sessão longa?
O modelo precisa reprocessar todo o prefixo do zero, aumentando tokens de entrada, custo e tempo até o primeiro token. O VS Code agora alerta usuários sobre isso via indicadores de estado de cache, algo mencionado como futuro trabalho no artigo-fonte, mas já implementado em versões recentes do Stable.
Fontes
- code.visualstudio.comfonte original
- Categoria
- CEVIU DevOps
- Publicado
- 03 de julho de 2026
- Editoria
- CEVIU DevOps