Crítica como habilidade central do design na era da IA
Aprofundamento CEVIU
Aprofundamento
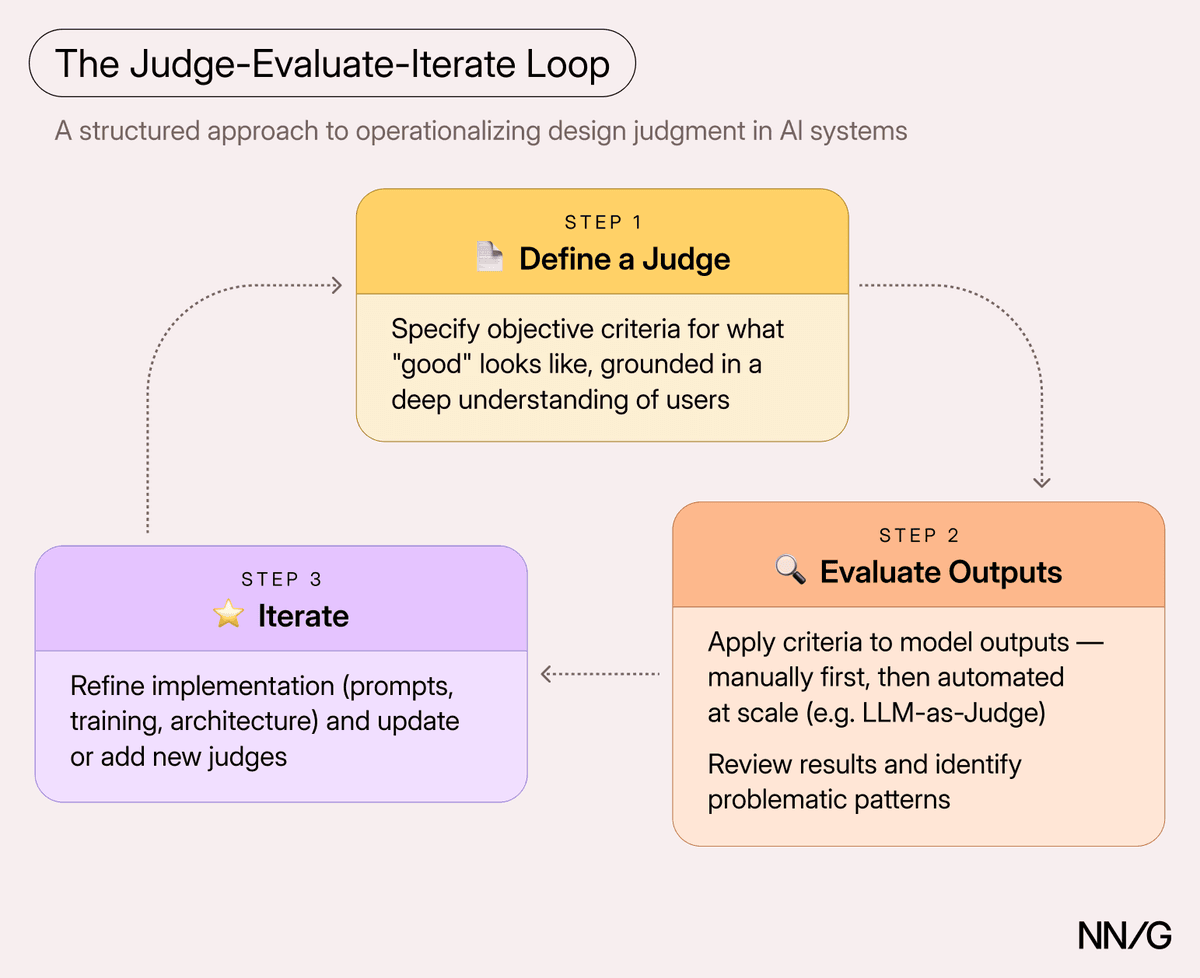
O designer deixou de ser o autor de telas estáticas para virar o guardião de um sistema vivo: cada prompt, cada contexto injetado, cada avaliação de saída é uma decisão de design que impacta a experiência real do usuário. Isso não é só sobre escrever melhor, é sobre construir um processo crítico repetível, com critérios objetivos (não subjetivos), treináveis por humanos e por IA. Um bom critério não diz 'a resposta deve soar empática', mas 'deve incluir exatamente um reconhecimento explícito da frustração do usuário + uma ação concreta com prazo definido'. Essa objetividade permite escalar avaliações com LLMs como juízes, desde que calibrados contra anotações humanas reais, com F1 ≥ 0.8. E isso já está em produção: times no Spotify DJ usam pares de respostas 'boas/ruins' para fine-tuning contínuo de agentes conversacionais; equipes no Notion AI monitoram em tempo real a fidelidade semântica de resumos com ferramentas como Galileo.
A crítica aqui não é uma etapa final, é o núcleo operacional. Ela se entrelaça com arquitetura de contexto (como mostramos em 15/06) e com o conceito de 'pronto' como processo contínuo (6/02). Designers nativos de IA hoje entregam não apenas prompts, mas conjuntos de testes de avaliação, bancos de casos de falha rotulados e definições de 'passou' que são auditáveis por engenheiros, cientistas de dados e até por compliance. É design como especificação executável, não mais em Figma, mas em código, dados e critérios mensuráveis.
O que mudou
Em abril, falávamos de designers como 'condutores' de protótipos funcionais. Hoje, esse papel evoluiu para 'árbitros de qualidade': não basta conduzir, é preciso julgar com rigor, medir com precisão e iterar com frequência. A grande mudança prática é que o ciclo judge-evaluate-iterate deixou de ser teórico, virou rotina em times que lançaram funcionalidades com IA em produção. Enquanto em 02/06 discutíamos o que significa 'pronto', agora temos equipes aplicando avaliação contínua em produção com monitoramento em tempo real via Galileo e Braintrust. E o que era uma comparação metafórica (IA como lâmpada mágica, 13/04) agora ganhou mecanismos concretos: critérios objetivos, F1 como métrica de confiança e pares de respostas para fine-tuning.
Por que isso importa
Porque erros de IA não são bugs, são desalinhamentos silenciosos entre intenção humana e comportamento probabilístico. Um chatbot que responde 'sim' a uma pergunta sobre risco de câncer pode passar em todos os testes unitários, mas falhar catastroficamente na prática. Crítica estruturada é a única barreira entre essa falha e o usuário. E ela é acessível: não exige PhD em ML, mas sim domínio de métodos de avaliação, habilidade de decompor necessidades em critérios observáveis e disciplina para manter o loop ativo, mesmo quando os resultados parecem estáveis. É a diferença entre projetar *para* a IA e projetar *com* ela, como parceira que precisa ser constantemente orientada, não programada.
Linha do tempo
CEVIU publica analogia da IA como lâmpada mágica, destacando o desafio de definir o 'o quê' em vez do 'como'
CEVIU define o designer nativo de IA como 'condutor' de protótipos funcionais, não tradutor de mockups
CEVIU introduz o conceito de 'design por dentro', com foco em código, dados reais e iterações rápidas
CEVIU redefine 'pronto' como processo contínuo, não estado estático, para funcionalidades com IA
CEVIU conclui, após 28 entrevistas, que pensamento crítico, não ferramentas, é a habilidade central do designer nativo de IA
CEVIU mostra que o design migrou do prompt engineering para a arquitetura de contexto como fronteira principal
Notícia atual: crítica estruturada se consolida como habilidade central, com ciclo judge-evaluate-iterate como prática operacional
Perguntas frequentes
Como transformar uma necessidade subjetiva ('a resposta deve ser empática') em um critério objetivo avaliável?
Quebre em elementos observáveis: presença de reconhecimento explícito da emoção do usuário (ex: 'entendo que isso é frustrante'), uso de linguagem ativa ('vamos resolver isso juntos'), e ausência de jargão técnico. Teste com 3+ avaliadores humanos: se >90% concordam em 80% dos casos, o critério está suficientemente objetivo.
Quando usar avaliação humana x avaliação por LLM-juíz?
Use humanos para definir critérios iniciais, calibrar o LLM-juíz e revisar falhas críticas (ex: segurança, ética, contexto sensível). Use LLM-juíz para escalar avaliações rotineiras, desde que tenha F1 ≥ 0.8 contra amostra humana representativa. Nunca substitua humanos em decisões de alto impacto.
Por que dividir critérios complexos em componentes menores melhora a avaliação?
Permite usar modelos menos potentes (e mais baratos) para partes objetivas (ex: verificação de contraste de cor via WCAG), enquanto reserva modelos avançados só para julgamentos sutis (ex: adequação do tom). Também facilita depuração: se um critério falha, você identifica exatamente qual componente gerou o problema.
O que fazer quando o modelo ignora mudanças no prompt?
Mude de estratégia: em vez de refinar o prompt, crie pares 'entrada → saída boa' e 'entrada → saída ruim' e use-os para fine-tuning supervisionado. Ou adicione camadas de validação pós-processamento, como um filtro determinístico que rejeita respostas com mais de 3 frases em interações rápidas.
Fontes
- nngroup.comfonte original
- Categoria
- CEVIU Design
- Publicado
- 16 de junho de 2026
- Editoria
- CEVIU Design